计算机科学入门
今天 我们来思考视觉的重要性,大部分人靠视觉来做饭,越过障碍,读路牌,看视频,以及无数其它任务。
视觉是信息最多的感官,比如周围的世界是怎样的,如何和世界交互,因此半个世纪来,计算机科学家一直在想办法让计算机有视觉。
因此诞生了 计算机视觉 (computer vision)这个领域,目标是让计算机 理解 图像和视频。

用过相机或手机的都知道,可以拍出有惊人保真度和细节的照片,比人类强得多,但正如计算机视觉教授 李飞飞 最近说的, 听到 不等于 听懂 , 看到 不等于 看懂 。
颜色跟踪算法
复习一下,图像是 像素 网格,每个像素的颜色通过三种 基色 定义:红,绿,蓝 。
通过组合三种颜色的 强度 ,可以得到任何颜色,也叫 RGB 值。
最简单的计算机视觉算法,最合适拿来入门的,是跟踪一个颜色物体,比如一个粉色的球。

首先,我们记下球的颜色, 保存 最中心像素的 RGB 值。
然后给程序喂入图像,让它找 最接近 这个颜色的像素。

算法可以从左上角开始,逐个检查像素,计算和目标颜色的差异,检查了每个像素后,最贴近的像素,很可能就是球。
不只是这张图片,我们可以在视频的每一帧图片跑这个算法, 跟踪 球的位置。
当然,因为光线,阴影和其它影响,球的颜色会有变化,不会和存的 RGB 值完全一样,但会很接近。
如果情况更极端一些,比如比赛是在晚上,追踪效果可能会很差,如果球衣的颜色和球一样,算法就完全晕了,因此很少用这类颜色跟踪算法,除非环境可以严格控制。
颜色跟踪算法 是一个个像素搜索,因为颜色是在一个像素里,但这种方法不适合占多个像素的特征,比如物体的边缘,是多个像素组成的。
卷积
为了识别这些特征,算法要一块块像素来处理,每一块都叫 块 (patches)。
举个例子,找垂直边缘的算法,假设用来帮无人机躲避障碍。

为了简单,我们把图片转成灰度,不过大部分算法可以处理颜色。

放大其中一个杆子,看看 边缘 是怎样的,可以很容易地看到杆子的左边缘从哪里开始,因为有垂直的颜色变化。

我们可以弄个规则说,某像素是垂直边缘的可能性,取决于左右两边像素的颜色 差异 程度。
左右像素的区别越大,这个像素越可能是边缘,如果色差很小,就不是边缘。

这个操作的数学符号看起来像这样,这叫 核 (kernel)或 过滤器 (filter),里面的数字用来做像素乘法,总和存到中心像素里。
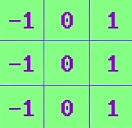
我们来看个实际例子,我已经把所有像素转成了灰度值。

现在把 核 的中心,对准感兴趣的像素。

这指定了每个像素要乘的值,然后把所有数字加起来,在这里,最后结果是 147 ,成为新像素值。

把核应用于像素块,这种操作叫 卷积 (convolution)。

现在我们把 核 应用到另一个像素,结果是 1 ,色差很小,因此这个点不是边缘。

如果把 核 用于照片中每个像素,结果会像这样,垂直边缘的像素值很高。

注意,水平边缘(比如背景里的平台)几乎看不见,如果要突出这些特征,要用不同的 核 ,用对水平边缘敏感的 核 。

这两个边缘增强的核叫 Prewitt算子 ,以发明者命名。
这只是众多 核 的两个例子, 核 能做很多种图像转换,比如这个 核 能锐化图像。

这个 核 能模糊图像。

核 也可以像饼干模具一样,匹配 特定 形状。
Photoshop 等图片编辑软件的各种滤镜就是不同的核。
维奥拉·琼斯人脸检测算法
之前做边缘检测的 核 ,会检查左右或上下的差异,但我们也可以做出擅长找线段的 核 ,或者包了一圈对比色的区域,这类 核 可以描述简单的形状,比如鼻梁往往比鼻子两侧更亮,所以线段敏感的 核 对这里的值更高。

眼睛也很独特,一个黑色圆圈被外层更亮的一层像素包着,有其它 核 对这种模式敏感。

当计算机扫描图像时,最常见的是用一个窗口来扫,可以找出人脸的特征组合,虽然每个 核 单独找出脸的能力很弱,但 组合 在一起会相当准确。

不是脸但又有一堆脸的特征在正确的位置,这种情况不太可能。
这是一个早期很有影响力的算法的基础,叫 维奥拉·琼斯人脸检测算法 (Viola-Jones Face Detection)。
卷积神经网络
如今的热门算法是 卷积神经网络 (Convolutional Neural Networks),我们上次谈了 神经网络 (Neural Networks),如果需要可以去看看。
总之,神经网络的最基本单位,是 神经元 ,它有多个输入,然后会把每个输入乘一个 权重 值,然后求总和,听起来好像挺耳熟,因为它很像 卷积 。
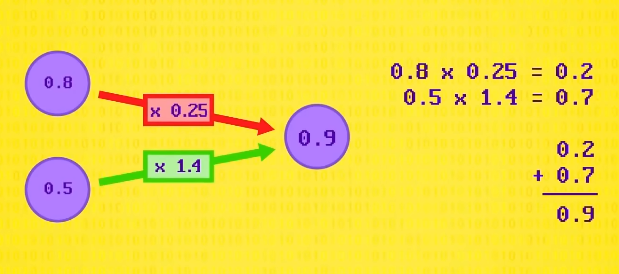
实际上,如果我们给神经元输入二维像素,完全就像 卷积 ,输入权重等于 核 的值,但和预定义 核 不同,神经网络可以 学习 对自己有用的 核 ,来识别图像中的特征。
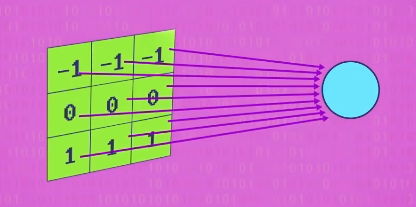
卷积神经网络 用一堆神经元处理图像数据,每个都会输出一个新图像,本质上是被 不同 的 核 处理了,输出会被后面一层神经元处理,卷积卷积再卷积。
第一层可能会发现 边缘 这样的特征,单次卷积可以识别出这样的东西,之前说过,下一层可以在这些基础上识别,比如由 边缘 组成的角落,然后下一层可以在 角落 上继续卷积一些可能有识别简单物体的神经元,比如 嘴 和 眉毛 ,然后不断重复,逐渐增加复杂度,直到某一层把 所有 特征放到一起: 眼睛,耳朵,嘴巴,鼻子 ,原来这是一张脸!
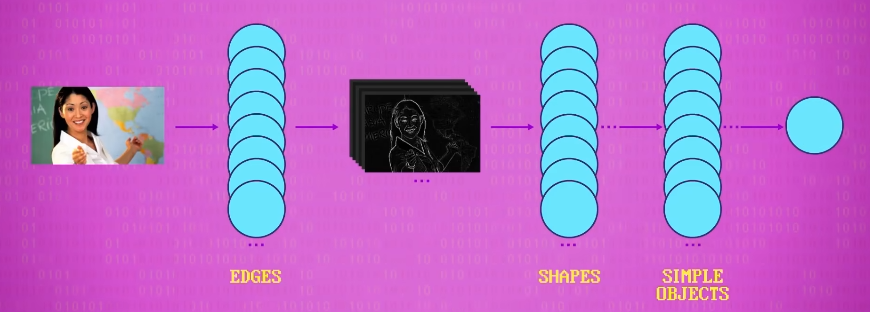
卷积神经网络 不是非要很多很多层,但一般会有很多层,来识别复杂物体和场景,所以算是 深度学习 。
维奥拉·琼斯 和 卷积神经网络 ,不只是认人脸,还可以识别手写文字,在CT扫描中发现肿瘤,监测马路是否拥堵。
但我们这里接着用人脸举例,不管用什么算法,识别出脸之后,可以用 更专用 的计算机视觉算法,来定位面部标志,比如 鼻尖 和 嘴角 ,有了标志点,判断眼睛有没有张开就很容易了,只是点之间的距离罢了。

也可以跟踪 眉毛 的位置,眉毛相对眼睛的位置可以代表惊喜或喜悦。

根据 嘴巴 的标志点,检测出微笑也很简单,这些信息可以用 情感识别算法 来识别,让电脑知道你是开心,忧伤,沮丧,困惑等等。

然后计算机可以做出合适的行为,比如当你不明白时给你提示,你心情不好时,就不弹更新提示了。
这只是计算机通过视觉感知周围的一个例子,不只是物理环境,比如是不是在上班,或是在火车上;还有社交环境,比如是朋友的生日派对,还是正式商务会议。
你在不同环境会有不同行为,计算机也应如此,如果它们够聪明的话……
面部标记点 也可以捕捉脸的形状,比如两只眼睛之间的距离,以及前额有多高,做生物识别,让有摄像头的计算机能认出你,不管是手机解锁还是政府用摄像头跟踪人,人脸识别有无限应用场景。

另外跟踪手臂和全身的标记点,最近也有一些突破,让计算机理解用户的身体语言,比如用户给联网微波炉的手势。

正如系列中常说的, 抽象 是构建复杂系统的关键,计算机视觉也是一样,硬件层面,有工程师在造更好的摄像头,让计算机有越来越好的视力,我自己的视力却不能这样。
用来自摄像头的数据可以用视觉算法找出脸和手,然后可以用其他算法接着处理,解释图片中的东西,比如用户的表情和手势,有了这些,人们可以做出新的交互体验,比如智能电视和智能辅导系统,会根据用户的手势和表情来回应。
这里的每一层都是活跃的研究领域,每年都有突破,这只是冰山一角,如今计算机视觉无处不在,商店里扫条形码,等红灯的自动驾驶汽车,或是抖音里添加胡子的特效。
令人兴奋的是一切才刚刚开始,最近的技术发展,比如超快的 GPU ,会开启越来越多可能性,视觉能力达到人类水平的计算机,会彻底改变交互方式,当然,如果计算机能听懂我们然后回话,就更好了。