数据流
从 JDK1.8 开始,Java 开始更多地融合大数据的操作模式,其中最具有代表性的就是提供了 Stream 接口,同时利用 Stream 接口可以实现 MapReduce 操作。本节将为读者讲解 Stream 数据流的相关操作。
数据流基础操作
从 JDK1.8 开始发现整个类集里面所提供的接口都出现了大量的 default 或 static 方法。如果读者细心观察过 Java Doc 文档可以发现,在 Iterable 接口( Collection 的父接口) 里面定义了一个方法以实现集合的输出:default void forEach(Consumer<?super T>action) )。在本方法中需要传递一个消费型的函数式接口,主要是设置输出的位置,例如,在屏幕上显示集合的内容,可以进行Sysetm.out.println() 方法的引用。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.forEach(System.out::println); // 引用forEach输出
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.forEach(System.out::println); // 引用forEach输出
}
}本程序并没有使用 Iterator 接口,但是由于使用消费型功能函数,所以只能实现输出操作,而不能针对每个数据进行处理。因此,forEach() 方法对实际的开发并没有实际的用处。
使用 Iterator 接口输出数据的目的是在每次迭代操作时都可以针对集合的每一个数据进行处理。所以在 JDK1.8 中为了简化集合数据处理的操作,专门提供了一个数据流操作接口:java.util.stream.Stream ,而这个类可以利用 Collection 接口提供的 default 型方法实现 Stream 接口的实例化操作:default Stream<E> stream() 。
当取得Stream 接口对象后,就可以使用此接口中的方法进行数据的操作 Stream 接口的常用方法如表所示。
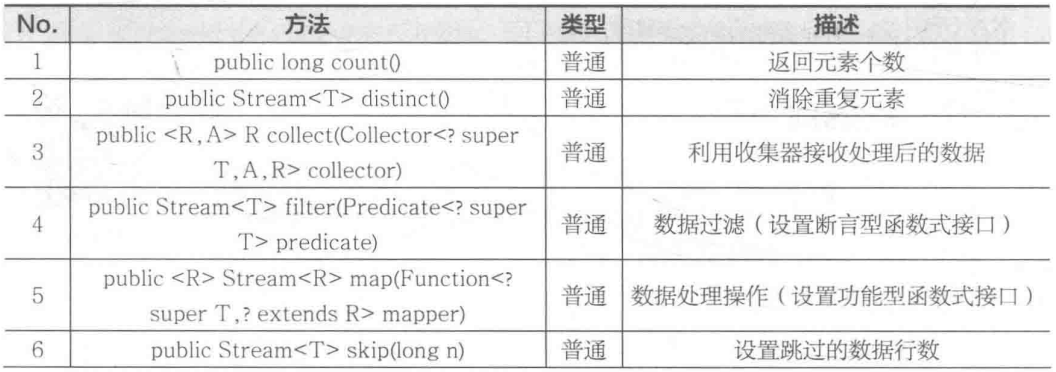
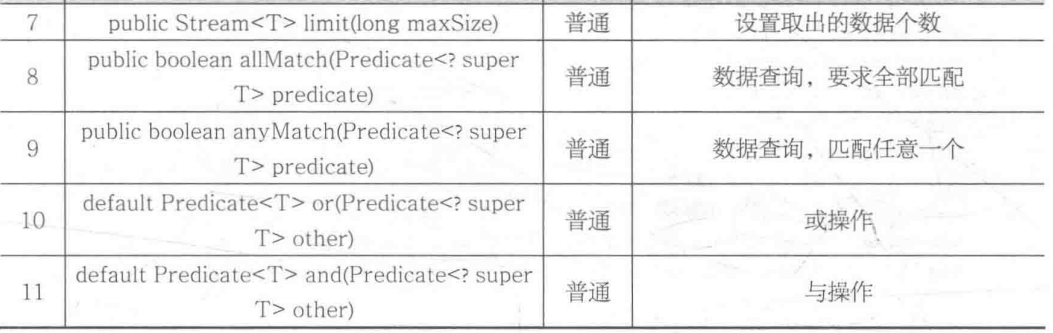
在表列出的方法中,collect() 方法主要是进行数据的收集操作,同时收集完成的数据可以通过 Collectors 类中的方法设置返回的集合类型,例如,使用 toList() 方法返回List集合,使用 toSet() 方法可以返回 Set 集合。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得了Stream类的对象
System.out.println(stream.count()); // 取得数据个数
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得了Stream类的对象
System.out.println(stream.count()); // 取得数据个数
}
}本程序首先利用 Collection 接口中的 stream() 方法将集合转化为数据流的形式,然后利用 Stream 类中的 count() 方法取得了数据流中所保存的元素个数。
实际上取得 Stream 接口对象的目的并不只是取得保存元素的数量,关键是利用 Stream 接口实现数据的加工处理操作。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复数据后形成新的List集合数据,里面不包含重复内容的集合
List<String> newAll = stream.distinct().collect(Collectors.toList()) ;
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复数据后形成新的List集合数据,里面不包含重复内容的集合
List<String> newAll = stream.distinct().collect(Collectors.toList()) ;
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}本程序首先在给出的 List 集合中保存了重复数据内容,然后利用 distinct() 方法将所有不重复的元素数据转化为新的数据流对象,最后利用 collect() 方法将数据流中的数据保存为 List 集合。
除了可以将 Stream 接口中的数据保存为集合外,也可以利用 filter() 方法针对数据流中的数据进行数据过滤的操作,在执行过滤时需要设置一个断言型函数式接口的方法引用。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复元素后执行数据过滤操作,在过滤中由于需要断言型函数式接口,所以引用contains()方法
// 将满足过滤条件的数据利用收集器保存在新的List集合中
List<String> newAll = stream.distinct().
filter((x) -> x.contains("t")).collect(Collectors.toList());
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复元素后执行数据过滤操作,在过滤中由于需要断言型函数式接口,所以引用contains()方法
// 将满足过滤条件的数据利用收集器保存在新的List集合中
List<String> newAll = stream.distinct().
filter((x) -> x.contains("t")).collect(Collectors.toList());
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}本程序在消除完重复元素后使用 filter() 方法执行了数据过滤操作,由于 filter() 方法需要传递断言型的函数式接口,所以本次传递的是 containst() 方法,如果集合中包含字母 t (小写字母判断)则表示满足过滤,可以保存数据到新集合中。程序的操作分析如图所示。
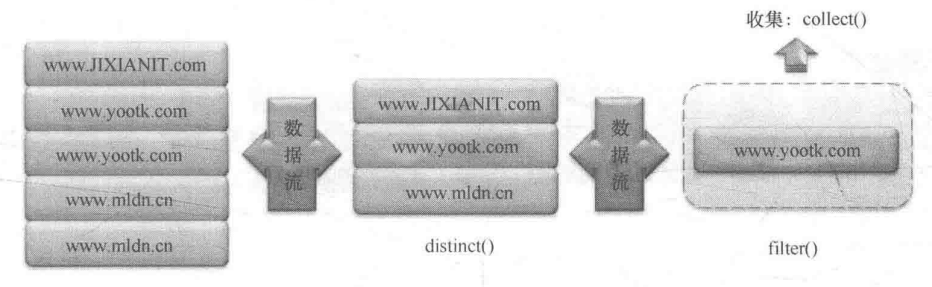
通过本程序查询结果可以发现一个问题:所有使用 filter() 方法过滤的数据只能针对数据流中已有的原始数据进行判断,也就是说此时并不能在过滤执行前对数据进行先期的处理,为了解决这个问题,可以在调用 filter() 方法,之前先调用 map() 方法。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复元素后执行数据过滤操作,在对集合中数据操作时将每条数据统一转为小写
// 在过滤中由于需要断言型函数式接口,所以引用contains()方法,此时只判断小写字母
// 将满足过滤条件的数据利用收集器保存在新的List集合中
List<String> newAll = stream.distinct().map((x) -> x.toLowerCase()).
filter((x) -> x.contains("t")).collect(Collectors.toList());
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复元素后执行数据过滤操作,在对集合中数据操作时将每条数据统一转为小写
// 在过滤中由于需要断言型函数式接口,所以引用contains()方法,此时只判断小写字母
// 将满足过滤条件的数据利用收集器保存在新的List集合中
List<String> newAll = stream.distinct().map((x) -> x.toLowerCase()).
filter((x) -> x.contains("t")).collect(Collectors.toList());
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}本程序在执行 filter() 方法前首先调用了 map() 方法,利用 map() 方法自动将集合中的每一条数据进行转小写的处理,这样通过filter() 方法过滤后的数据内容都会以小写字母的形式出现。数据流处理如图所示。
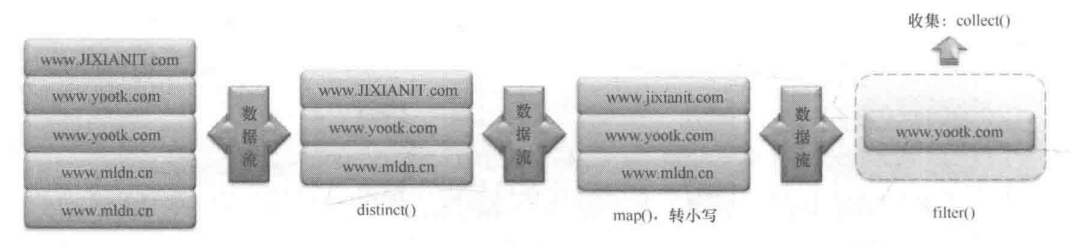
在数据流的操作中也可以轻松地实现数据的分页操作,此时只需要使用 skip() 与 limit() 两个方法控制即可。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复元素后执行数据过滤操作,在对集合中数据操作时将每条数据统一转为小写
// 在过滤中由于需要断言型函数式接口,所以引用contains()方法,此时只判断小写字母
// 执行完数据过滤后进行数据的分页操作,跳过1行数据,取出1行数据
// 将满足过滤条件的数据利用收集器保存在新的List集合中
List<String> newAll = stream.distinct().map((x) -> x.toLowerCase()).
filter((x) -> x.contains("t")).skip(1).limit(1).
collect(Collectors.toList());
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
// 去掉重复元素后执行数据过滤操作,在对集合中数据操作时将每条数据统一转为小写
// 在过滤中由于需要断言型函数式接口,所以引用contains()方法,此时只判断小写字母
// 执行完数据过滤后进行数据的分页操作,跳过1行数据,取出1行数据
// 将满足过滤条件的数据利用收集器保存在新的List集合中
List<String> newAll = stream.distinct().map((x) -> x.toLowerCase()).
filter((x) -> x.contains("t")).skip(1).limit(1).
collect(Collectors.toList());
newAll.forEach(System.out :: println); // 取得消除重复数据后的内容
}
}本程序在数据流处理与过滤执行完毕后使用 skip() 跨过了第 1 条数据,然后利用 limit() 限定了要取 1 条数据,由于经过处理后的数据只有 2 条内容,所以只有第 2 条数据被收集到了新的集合中。
在 Stream 数据流中也可以结合断言型接口实现数据的检索操作,此时可以使用 allMatch() 或 anyMatch() 两个方法完成。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
if (stream.anyMatch((x) -> x.contains("yootk"))) {
System.out.println("数据存在!");
}
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Stream<String> stream = all.stream() ; // 取得Stream类的对象
if (stream.anyMatch((x) -> x.contains("yootk"))) {
System.out.println("数据存在!");
}
}
}本程序直接利用 Stream 数据流中的 anyMatch() 方法结合断言型函数式接口的操作,判断是否存在指定的数据,如果存在数据则进行信息提示。不管使用 allMatch() 或 anyMatch() 方法,都只能接收一种数据验证条件,如果要同时匹配多个条件,则可以利用 or() 或 and() 方法实现逻辑操作。
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Predicate;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Predicate<String> p1 = (x) -> x.contains("yootk") ; // 断言型接口方法引用
Predicate<String> p2 = (x) -> x.contains("mldn") ; // 断言型接口方法引用
Stream<String> stream = all.stream() ; // 取得Stream类的对象
if (stream.anyMatch(p1.or(p2))) { // 两个条件有一个满足即可
System.out.println("数据存在!");
}
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Predicate;
import java.util.stream.Stream;
public class TestDemo {
public static void main(String[] args) throws Exception {
List<String> all = new ArrayList<String>(); // 实例化List集合接口
all.add("www.JIXIANIT.com"); // 保存数据,大写字母
all.add("www.yootk.com"); // 保存数据
all.add("www.yootk.com"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
all.add("www.mldn.cn"); // 保存数据
Predicate<String> p1 = (x) -> x.contains("yootk") ; // 断言型接口方法引用
Predicate<String> p2 = (x) -> x.contains("mldn") ; // 断言型接口方法引用
Stream<String> stream = all.stream() ; // 取得Stream类的对象
if (stream.anyMatch(p1.or(p2))) { // 两个条件有一个满足即可
System.out.println("数据存在!");
}
}
}本程序使用两个断言型的函数式接口,利用 or() 方法进行连接,这样就可以实现多个条件的判断。
MapReduce
MapReduce 是一种进行 大数据操作 的开发模型,在 Stream 数据流中也提供了类似的实现,其中有以下两个重要方法。
数据处理方法:
public <R> Stream <R> map(Function<? super T,? extends R> mapper);数据分析方法:
public Optional<T> reduce(BinaryOperator<T> accumulator)。
在实际使用中,可以先使用 map() 方法针对数据进行处理,再利用 reduce() 对数据进行分析。下面通过 3 个具体的范例来介绍此操作的使用。
关于 BinaryOperator 接口的说明
BinaryOperator 是 BiFunction 的子接口,也属于功能型的函数式接口。在这个接口里面定义了一个 apply() 方法( public R apply(Tt,Uu) )。
下面模拟一个网站用户购买数据的记录分析,为了可以保存相关的数据记录,可以将购买的商品信息保存在一个 Orders 类中
package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
class Orders {
private String pname ; // 商品名称
private double price ; // 商品单价
private int amount ; // 购买数量
public Orders(String pname,double price,int amount) {
this.pname = pname ;
this.price = price ;
this.amount = amount ;
}
public String getPname() {
return pname;
}
public int getAmount() {
return amount;
}
public double getPrice() {
return price;
}
}
public class TestDemo {
public static void main(String[] args) throws Exception {
List<Orders> all = new ArrayList<Orders>();
all.add(new Orders("Java开发实战经典", 79.8, 200)); // 添加购买记录
all.add(new Orders("JavaWeb开发实战经典", 69.8, 500)); // 添加购买记录
all.add(new Orders("Android开发实战经典", 89.8, 300)); // 添加购买记录
all.add(new Orders("Oracle开发实战经典", 99.0, 800)); // 添加购买记录
all.stream().
map((x) -> x.getAmount() * x.getPrice()). // 用于实现每件商品总价的计算
forEach(System.out::println); // 输出每一个商品的总价
}
}package com.yootk.demo;
import java.util.ArrayList;
import java.util.List;
class Orders {
private String pname ; // 商品名称
private double price ; // 商品单价
private int amount ; // 购买数量
public Orders(String pname,double price,int amount) {
this.pname = pname ;
this.price = price ;
this.amount = amount ;
}
public String getPname() {
return pname;
}
public int getAmount() {
return amount;
}
public double getPrice() {
return price;
}
}
public class TestDemo {
public static void main(String[] args) throws Exception {
List<Orders> all = new ArrayList<Orders>();
all.add(new Orders("Java开发实战经典", 79.8, 200)); // 添加购买记录
all.add(new Orders("JavaWeb开发实战经典", 69.8, 500)); // 添加购买记录
all.add(new Orders("Android开发实战经典", 89.8, 300)); // 添加购买记录
all.add(new Orders("Oracle开发实战经典", 99.0, 800)); // 添加购买记录
all.stream().
map((x) -> x.getAmount() * x.getPrice()). // 用于实现每件商品总价的计算
forEach(System.out::println); // 输出每一个商品的总价
}
}本类设计时专门设计出了商品的单价与数量,这样如果要取得某一个商品的花费就必须使用数量乘以单价。而这些操作可以利用 Stream 接口中的 map() 方法进行处理,而后利用 forEach() 方法就可以输出每一件商品总的花费。
范例实现了一个简单的 map() 操作,针对每一个数据分别进行了处理,但是只是将处理的结果进行了输出。如果要对 map() 处理后的数据进行统计操作,则可以利用 reduce() 方法完成。
public class TestDemo {
public static void main(String[] args) throws Exception {
List<Orders> all = new ArrayList<Orders>();
all.add(new Orders("Java开发实战经典", 79.8, 200)); // 添加购买记录
all.add(new Orders("JavaWeb开发实战经典", 69.8, 500)); // 添加购买记录
all.add(new Orders("Android开发实战经典", 89.8, 300)); // 添加购买记录
all.add(new Orders("Oracle开发实战经典", 99.0, 800)); // 添加购买记录
double allPrice = all.stream().
map((x) -> x.getAmount() * x.getPrice()). // 用于实现每件商品总价的计算
reduce((sum, m) -> sum + m).get(); // 输出每一个商品的总价
System.out.println("购买图书总价:" + allPrice);
}
}public class TestDemo {
public static void main(String[] args) throws Exception {
List<Orders> all = new ArrayList<Orders>();
all.add(new Orders("Java开发实战经典", 79.8, 200)); // 添加购买记录
all.add(new Orders("JavaWeb开发实战经典", 69.8, 500)); // 添加购买记录
all.add(new Orders("Android开发实战经典", 89.8, 300)); // 添加购买记录
all.add(new Orders("Oracle开发实战经典", 99.0, 800)); // 添加购买记录
double allPrice = all.stream().
map((x) -> x.getAmount() * x.getPrice()). // 用于实现每件商品总价的计算
reduce((sum, m) -> sum + m).get(); // 输出每一个商品的总价
System.out.println("购买图书总价:" + allPrice);
}
}本程序针对每件商品所花费的总价利用 reduce() 方法进行了求和运算,然后利用 Lambda 表达式实现了数据结果的累加操作。
范例只是实现了一个最简单的 MapReduce ,所完成的统计功能也过于有限,如果要实现更完善的统计操作,需要使用 Stream 接口里面定义的以下方法。
- 按照
Double进行数据处理:public DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper); - 按照
Int进行数据处理:public IntStream mapTolnt(TolntFunction<? super T> mapper); - 按照
Long进行数据处理:public LongStream mapToLong(ToLongFunction<? super T> mapper)。
以上列出的 3 种数据类型的处理方法中分别返回了 DoubleStream 、IntStream 、LongStream 接口实例,实际上这些接口与 Stream 接口都属于 BaseStrem 的子接口。数据流继承结构如图所示。
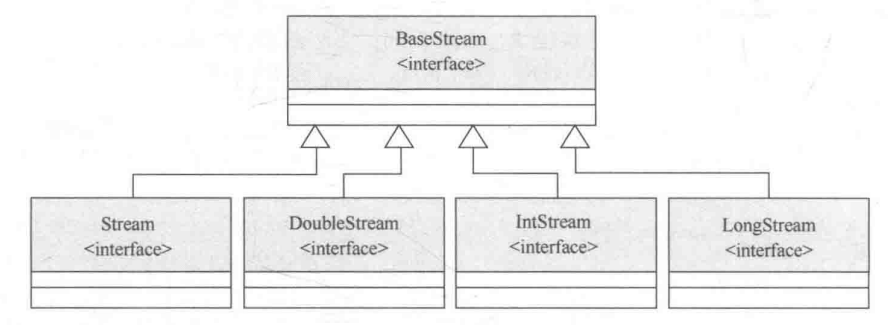
在给出的 DoubleStream 、IntStream 、LongStream 接口中分别提供了以下数据统计的操作方法。
DoubleStream提供的数据统计方法:public DoubleSummaryStatistics summaryStatistics();IntStream提供的数据统计方法:public IntSummaryStatistics summaryStatistics();LongStream提供的数据统计方法:public LongSummaryStatistics summaryStatistics()。
以 DoubleStream 接口中返回的 DoubleSummaryStatistics 类为例,在此类中提供了表所示的操作方法来实现数据的统计操作。
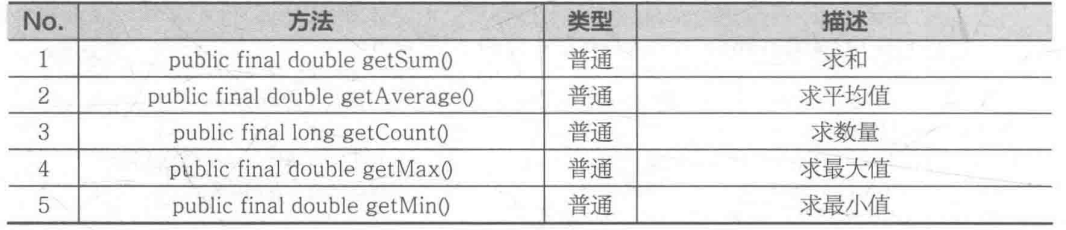
public class TestDemo {
public static void main(String[] args) throws Exception {
List<Orders> all = new ArrayList<Orders>();
all.add(new Orders("Java开发实战经典", 79.8, 200)); // 添加购买记录
all.add(new Orders("JavaWeb开发实战经典", 69.8, 500)); // 添加购买记录
all.add(new Orders("Android开发实战经典", 89.8, 300)); // 添加购买记录
all.add(new Orders("Oracle开发实战经典", 99.0, 800)); // 添加购买记录
DoubleSummaryStatistics dss = all.stream()
.mapToDouble((sc) -> sc.getAmount() * sc.getPrice()) // 数据处理
.summaryStatistics(); // 进行数据统计
System.out.println("商品个数:" + dss.getCount());
System.out.println("总花费:" + dss.getSum());
System.out.println("平均花费:" + dss.getAverage());
System.out.println("最高花费:" + dss.getMax());
System.out.println("最低花费:" + dss.getMin());
}
}public class TestDemo {
public static void main(String[] args) throws Exception {
List<Orders> all = new ArrayList<Orders>();
all.add(new Orders("Java开发实战经典", 79.8, 200)); // 添加购买记录
all.add(new Orders("JavaWeb开发实战经典", 69.8, 500)); // 添加购买记录
all.add(new Orders("Android开发实战经典", 89.8, 300)); // 添加购买记录
all.add(new Orders("Oracle开发实战经典", 99.0, 800)); // 添加购买记录
DoubleSummaryStatistics dss = all.stream()
.mapToDouble((sc) -> sc.getAmount() * sc.getPrice()) // 数据处理
.summaryStatistics(); // 进行数据统计
System.out.println("商品个数:" + dss.getCount());
System.out.println("总花费:" + dss.getSum());
System.out.println("平均花费:" + dss.getAverage());
System.out.println("最高花费:" + dss.getMax());
System.out.println("最低花费:" + dss.getMin());
}
}本程序实现了集合中保存数据的分析统计操作,由于计算的数据中会包含小数,所以使用了 DoubleSummaryStatistics 类进行数据统计操作。