计算机科学入门
我们之前说过,计算机很擅长存放,整理,获取和处理大量数据,很适合有上百万商品的电商网站,或是存几十亿条健康记录,方便医生看。

但如果想根据数据做决定呢?
机器学习
这是 机器学习 (machine learning)的本质,机器学习算法让计算机可以从数据中学习,然后自行做出预测和决定。
能自我学习的程序很有用,比如判断是不是垃圾邮件。
虽然有用,但我们不会说它有人类一般的智能,虽然 AI 和 ML 这两词经常混着用。
大多数计算机科学家会说,机器学习是为了实现人工智能这个更宏大目标的技术之一。
人工智能 (Artificial Intelligence)简称 AI ,机器学习和人工智能算法一般都很复杂,所以我们不讲具体细节重点讲概念。
分类器
我们从简单例子开始:判断飞蛾是 月蛾 还是 帝蛾 ,这叫 分类 (classification),做分类的算法叫 分类器 (classifier)。
虽然我们可以用照片和声音来训练算法,很多算法会减少复杂性,把数据简化成 特征 , 特征 是用来帮助 分类 的值。
对于之前的飞蛾分类例子,我们用两个特征: 翼展 和 重量 ,为了训练 分类器 做出好的预测,我们需要 训练数据 (training data)。
为了得到数据,我们派昆虫学家到森林里收集 月蛾 和 帝蛾 的数据,专家可以认出不同飞蛾,所以专家不只记录特征值,还会把种类也写上,这叫 标记数据 (labeled data)。
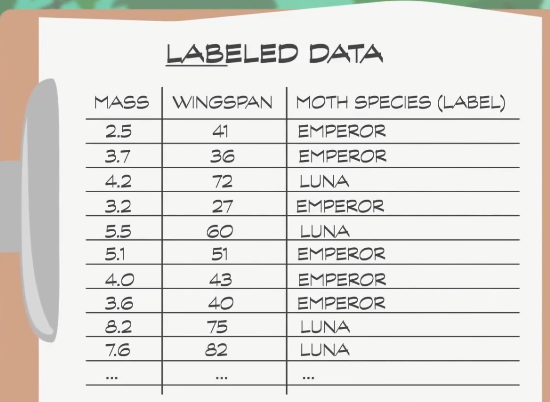
因为只有两个特征,很容易用散点图把数据视觉化,红色标了 100 个帝蛾,蓝色标了 100 个月蛾,可以看到大致分成了两组,但中间有一定 重叠 ,所以想完全 区分 两个组比较困难。
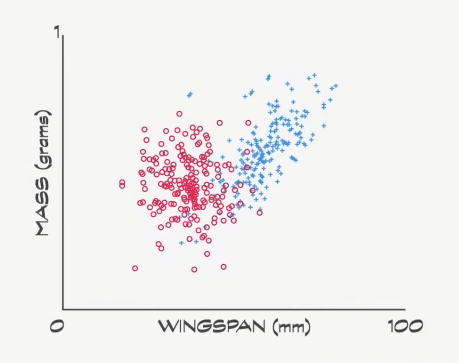
所以机器学习算法登场,找出 最佳 区分。
决策边界
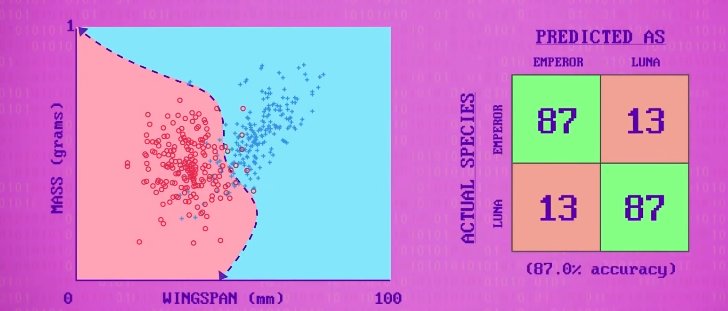
我用肉眼大致估算下,然后判断翼展小于 45 毫米的很可能是 帝蛾 ,可以再加一个条件,重量必须小于 0.75 ,才算是 帝蛾 。
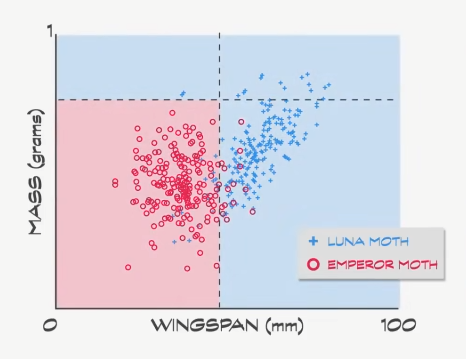
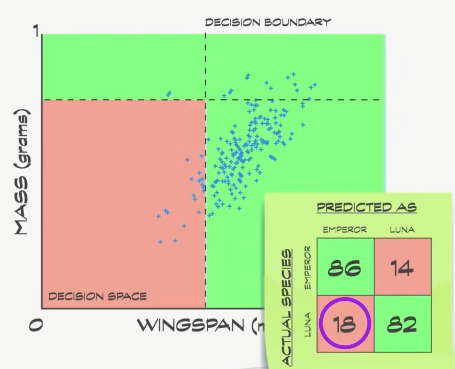
这些线叫 决策边界 (decision boundaries),如果仔细看数据,86 只帝蛾在正确的区域,但剩下 14 只在错误的区域;另一方面,82 只月蛾在正确的区域,18 个在错误的区域。
混淆矩阵
这里有个表记录 正确数 和 错误数 ,这表叫 混淆矩阵 (confusion matrix)。
注意我们没法画出 100% 正确分类的线,降低翼展的 决策边界 ,会把更多 帝蛾 误分类成 月蛾 ,如果提高,会把更多月蛾 **分错类 ** 。
机器学习算法的目的,是 最大化正确分类 + 最小化错误分类 。
在训练数据中,有 168 个正确,32 个错误,平均准确率 84% 。
用这些决策边界,如果我们进入森林,碰到一只不认识的飞蛾,我们可以测量它的特征,并绘制到决策空间上,这叫 未标签数据 (unlabeled data)。
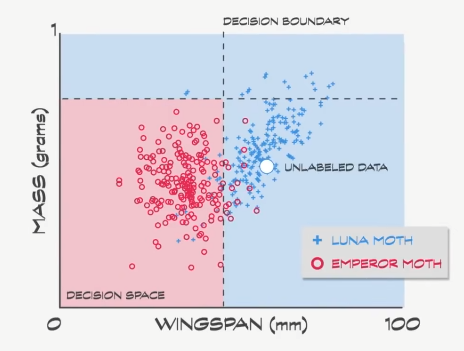
决策边界可以 猜测 飞蛾种类,这里我们预测是 月蛾 。
决策树
这个把决策空间切成几个盒子的简单方法,可以用 决策树 (decision tree)来表示,画成图像,会像这样。
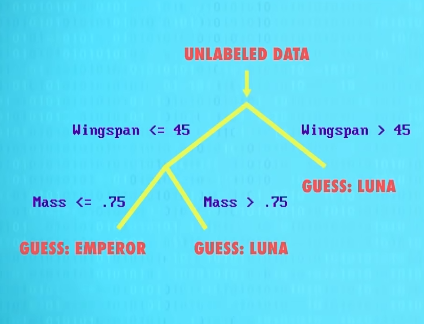
用 if 语句写代码,这样生成决策树的机器学习算法。

需要选择用什么特征来分类,每个特征用什么值, 决策树 只是机器学习的一个简单例子,如今有数百种算法,而且新算法不断出现,一些算法甚至用 多个 决策树 来预测,计算机科学家叫这个 森林 ,因为有多颗树嘛。
支持向量机
也有不用树的方法,比如 支持向量机 (Support Vector Machines),本质上是用 任意线段 来切分 决策空间 ,不一定是直线,可以是 多项式 或其他 数学函数 。
就像之前,机器学习算法负责找出最好的线,最准的决策边界。
之前的例子只有两个特征,人类也可以轻松做到,如果加第 3 个特征,比如 触角长度 ,那么 2D 线段,会变成 3D 平面,在三个维度上做决策边界。
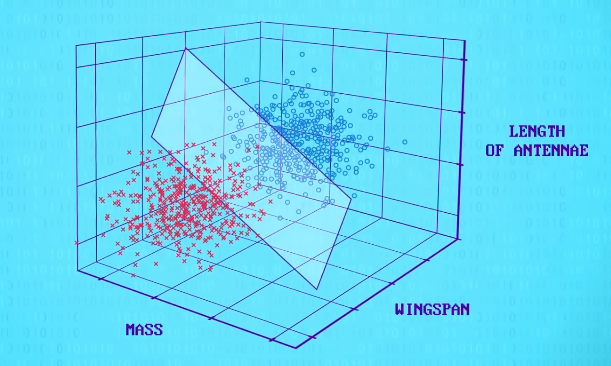
这些平面 不必 是直的,而且真正有用的分类器会有很多飞蛾种类,你可能会同意现在变得太复杂了。
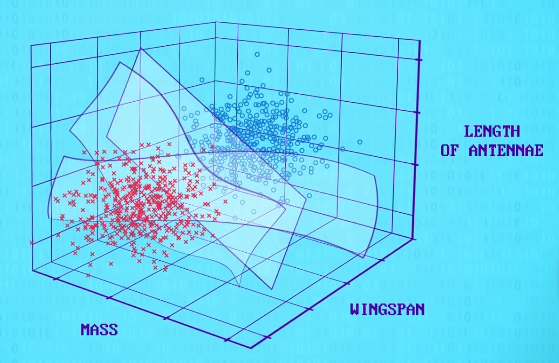
但这也只是个简单例子,只有 3 个特征和 5 个品种,我们依然可以用 3D 散点图画出来。
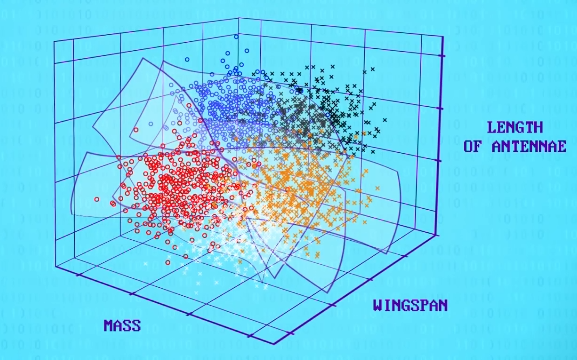
不幸的是,一次性看 4 个或 20 个特征,没有好的方法,更别说成百上千的特征了,但这正是机器学习要面临的问题。
你能想象靠手工在一个上千维度的决策空间里,给 超平面 (Hyperplane)找出一个方程吗,大概不行,但聪明的机器学习算法可以做到。
Google,Facebook,微软和亚马逊的计算机里,整天都在跑这些算法。
决策树 和 支持向量机 这样的技术,发源自 统计学 ,统计学早在计算机出现前,就在用数据做决定。
神经网络
有一大类机器学习算法用了统计学,但也有不用统计学的算法,其中最值得注意的是 人工神经网络 (artificial neural networks) ,灵感来自大脑里的 神经元 (neurons)。
神经元是 细胞 ,用 电信号 和 化学信号 来处理和传输消息,它从其他细胞得到一个或多个输入,然后处理信号并发出信号,形成巨大的 互联网络 ,能处理复杂的信息。
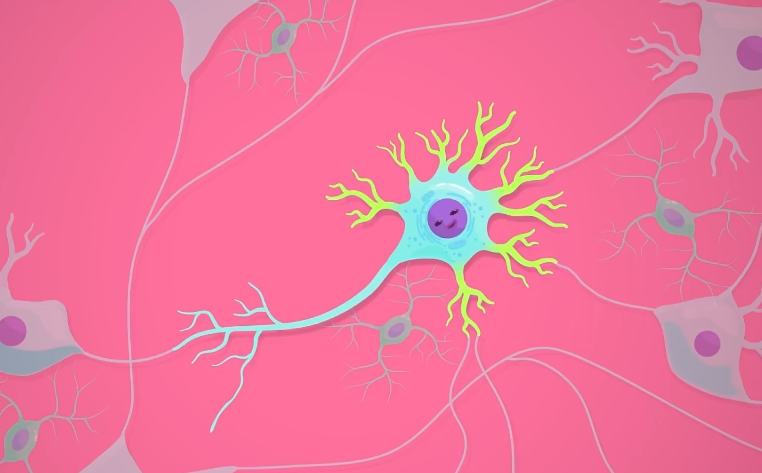
人造神经元很类似,可以接收多个输入,然后整合并发出一个信号,它不用电信号或化学信号,而是吃数字进去,吐数字出来,它们被放成一层层,形成神经元网络,因此得名 神经网络 (neural networks)。
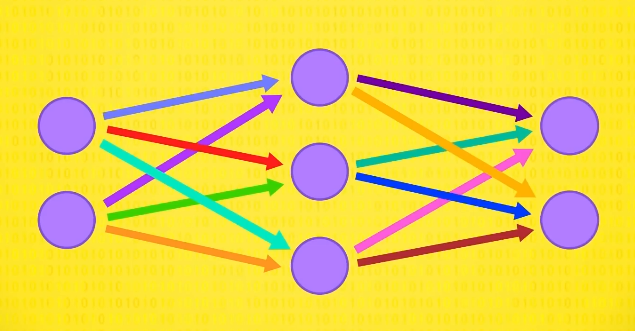
回到飞蛾例子,看如何用神经网络分类。
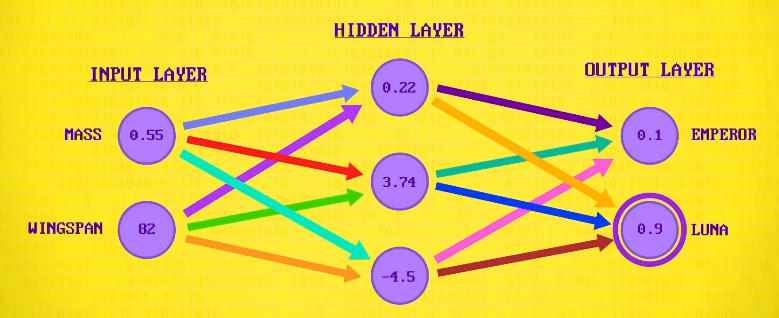
我们的第一层,输入层。
提供需要被分类的单个飞蛾数据,同样,这次也用 重量 和 翼展 ,另一边是输出层,有两个神经元:一个是 帝蛾 ,一个是 月蛾 。
2 个神经元里最兴奋的就是分类结果,中间有一个 隐藏层 ,负责把输入变成输出,负责干分类这个重活。
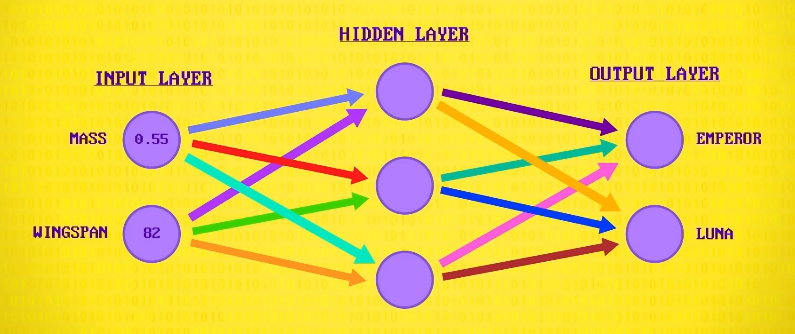
为了看看它是如何分类的,我们放大 隐藏层 里的一个神经元,神经元做的第一件事,是把每个输入乘以一个 权重 ,假设 2.8 是第一个输入,0.1 是第二个输入。
TIP
这些权重,偏差值等只是假设,需要通过 不断试错 找出正确的值,也就是机器学习。
在机器学习中, 算法、算力、数据 缺一不可,大数据时代可以提供海量数据,现在正处于机器学习发展的黄金时期!
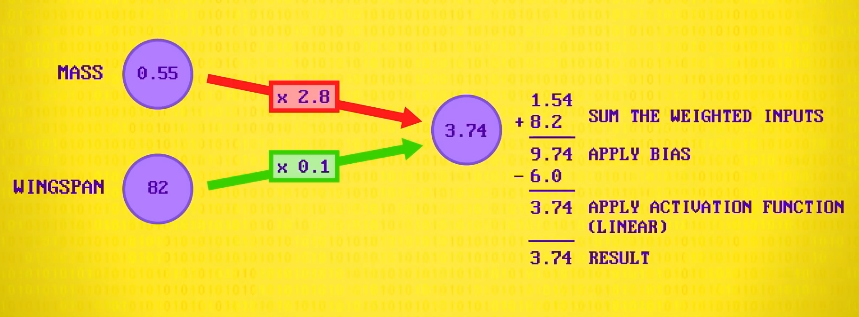
然后它会相加输入,总共是 9.74 ,然后对这个结果,用一个 偏差值 处理,意思是加或减一个固定值。比如 -6 ,得到 3.74 。
做神经网络时,这些偏差和权重,一开始会设置成 随机值 ,然后算法会 调整 这些值来训练神经网络,使用 标记数据 来训练和测试,逐渐提高准确性,很像人类学习的过程。
最后,神经元有 激活函数 ,它也叫 传递函数 ,会应用于输出,对结果执行最后一次数学修改,例如,把值限制在 -1 和 +1 之间,或把负数改成 0 ,这次我们用 线性 (linear)传递函数,它不会改变值,所以 3.74 还是 3.74 。
所以这里的例子,输入 0.55 和 82 ,输出 3.74 ,这只是一个神经元。
但 加权,求和,偏置,激活函数 会应用于一层里的 每个 神经元,并向前传播,一次一层,数字最高的就是结果: 月蛾 。
深度学习
重要的是,隐藏层不是只能有一层,可以有很多层, 深度学习 (deep learning)因此得名。
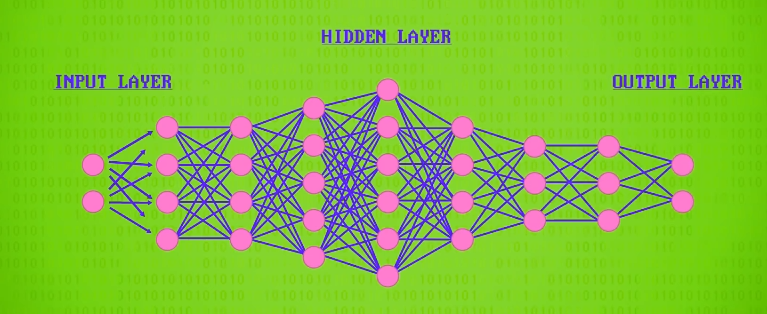
训练更复杂的网络需要更多的计算量和数据,尽管神经网络 50 多年前就发明了,深层神经网络直到最近才成为可能,感谢强大的处理器和超快的 GPU ,感谢游戏玩家对帧率的苛刻要求!
AI
几年前,Google 和 Facebook 展示了深度神经网络,在照片中识别人脸的准确率,和人一样高,这是个巨大的里程碑。

现在有深层神经网络开车,翻译,诊断医疗状况等等,这些算法非常复杂,但还不够 "聪明" ,它们只能做 一件事 ,分类飞蛾,找人脸,翻译,这种AI叫 弱AI 或 窄AI ,只能做特定任务。
但这不意味着它没用,能自动做出诊断的医疗设备,和自动驾驶的汽车真是太棒了!
但我们是否需要这些计算机来创作音乐,在空闲时间找美味食谱呢?也许不要,如果有的话还挺酷的。
真正通用的,像人一样聪明的 AI ,叫 强AI ,目前没人能做出来接近人类智能的AI。
TIP
ChatGPT 是最接近强 AI 的人工智能模型。
有人认为不可能做出来,但许多人说数字化知识的爆炸性增长,比如维基百科,网页和 Youtube 视频,是 强AI 的完美引燃物。
你一天最多只能看 24 小时的 YouTube ,计算机可以看上百万小时。
比如,IBM 的沃森吸收了 2 亿个网页的内容,包括维基百科的全文,虽然不是 强AI 但沃森也很聪明,在 2011 年的知识竞答中碾压了人类。

AI 不仅可以吸收大量信息,也可以不断学习进步,而且一般比人类快得多,2016 年 Google 推出 AlphaGo ,一个会玩围棋的 窄AI ,它和自己的克隆版下无数次围棋,2017 年 AlphaGo 击败当时世界排名第一的棋手柯洁。
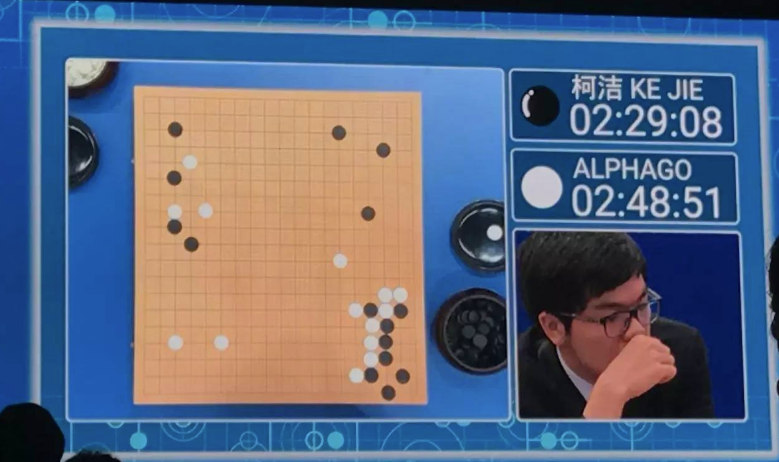
学习什么管用,什么不管用,自己发现成功的策略,这叫 强化学习 (Reinforcement Learning)是一种很强大的方法,和人类的学习方式非常类似。
人类不是天生就会走路,是上千小时的试错学会的,计算机现在才刚学会 反复试错 来学习,对于很多狭窄的问题,强化学习已被广泛使用。
有趣的是,如果这类技术可以更广泛地应用,创造出类似人类的 强AI ,能像人类小孩一样学习,但学习速度超快,如果这发生了,对人类可能有相当大的影响,我们以后会讨论。