链表
链表 是一种根据元素节点逻辑关系排列起来的一种 数据结构 。利用链表可以保存多个数据,这一点类似于数组的概念,但是数组本身有一个缺点一数组的长度固定,不可改变。在长度固定的情况下首选的肯定是数组,但是在现实的开发中往往要保存的内容长度是不确定的,此时就可以利用链表结构来代替数组的使用。
关于链表的掌握说明
对于程序开发人员而言,个人总结有三大基本功:程序逻辑、数据结构 SQL语句 。其中数据结构的学习最为麻烦,因为如果只是单纯地学习理论是没有任何意义的,但如果要实现数据结构又需要读者充分理解方法的递归调用、引用传递等概念。
所以对于本部分内容,笔者并没有要求读者必须掌握,而之所以会讲解数据结构,主要目的有两个:第一个目的是进一步巩固前面学习的基础知识,第二个目的是为 类集框架 打下概念基础。如果读者觉得过于困难,可以忽略复杂的实现代码,而将更多的学习精力用于记住所讲解方法的定义(包括方法名称、参数作用)以及方法的实现原理描述上,这样对于后面的学习也有很大帮助。
另外如果本身技术已经很好的读者,笔者强烈建议可以自己试着写出一个链表操作,因为在一些公司的笔试中也会出现让读者编写链表或二叉树的数据结构。
链表的基本形式
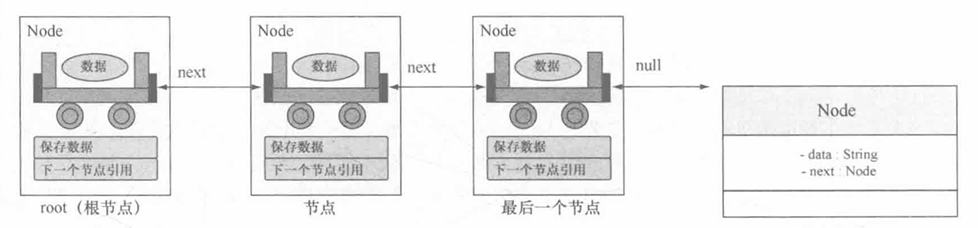
链表是一种最为简单的数据结构,它的主要目的是依靠引用关系来实现多个数据的保存。下面假设要保存的数据是字符串(引用类型) ,则可以按照下图所示的关系进行保存。
可以发现,所有要保存的数据都会被包装到一个节点对象中,之所以会引用一个节类,是因为只依靠保存的数据无法区分出先后顺序,而引入了 Node 类可以包装数据并指向下一个节点,所以在 Node 类的设计中主要保存两个属性:数据(data)与下一个节点引用 (next)。
class Node { // 每一个链表实际上就是由多个节点组成的
private String data; // 要保存的数据
private Node next; // 要保存的下一个节点
/**
* 每一个Node类对象都必须保存有相应的数据
* @param data 要通过节点包装的数据
*/
public Node(String data) { // 必须有数据才有Node
this.data = data;
}
/**
* 设置下一个节点关系
* @param next 保存下一个Node类引用
*/
public void setNext(Node next) {
this.next = next;
}
/**
* 取得当前节点的下一个节点
* @return 当前节点的下一个节点引用
*/
public Node getNext() {
return this.next;
}
/**
* 设置或修改当前节点包装的数据
* @param data
*/
public void setData(String data) {
this.data = data;
}
/**
* 取得包装的数据
* @return
*/
public String getData() {
return this.data;
}
}class Node { // 每一个链表实际上就是由多个节点组成的
private String data; // 要保存的数据
private Node next; // 要保存的下一个节点
/**
* 每一个Node类对象都必须保存有相应的数据
* @param data 要通过节点包装的数据
*/
public Node(String data) { // 必须有数据才有Node
this.data = data;
}
/**
* 设置下一个节点关系
* @param next 保存下一个Node类引用
*/
public void setNext(Node next) {
this.next = next;
}
/**
* 取得当前节点的下一个节点
* @return 当前节点的下一个节点引用
*/
public Node getNext() {
return this.next;
}
/**
* 设置或修改当前节点包装的数据
* @param data
*/
public void setData(String data) {
this.data = data;
}
/**
* 取得包装的数据
* @return
*/
public String getData() {
return this.data;
}
}Node 节点类本身 不属于 一个简单 Java 类,而是一个功能性的表示类,在这个类中,主要保存了两种数据:一种是存储的对象 (此处暂时保存的是 String 型对象),另一种存储的是当前节点的下一个节点(next)。
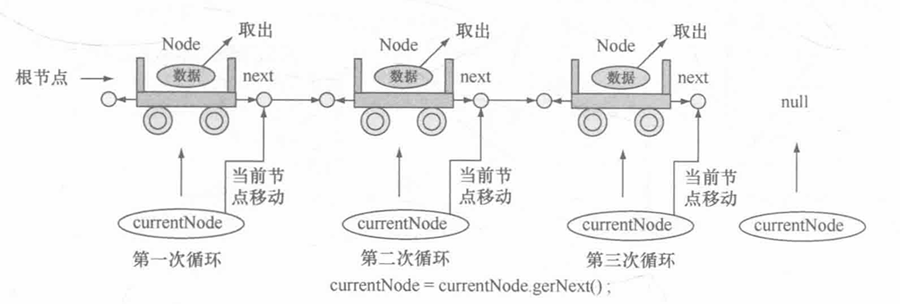
在进行链表操作的时候,首先需要的是一个 根节点 (第一个节点即为根节点),然后每一个节点的引用都保存在上一节点的 next 属性中。而在进行输出的时候也应该按照节点的先后顺序,一个一个取得每一个节点所包装的数据,如图所示。
public class LinkDemo {
public static void main(String args[]) {
// 第一步:定义要操作的节点并设置好包装的字符串数据
Node root = new Node("火车头") ; // 定义节点,同时包装数据
Node n1 = new Node("车厢A") ; // 定义节点,同时包装数据
Node n2 = new Node("车厢B") ; // 定义节点,同时包装数据
root.setNext(n1) ; // 设置节点关系
n1.setNext(n2) ; // 设置节点关系
// 第二步:根据节点关系取出所有数据
Node currentNode = root ; // 当前从根节点开始读取
while (currentNode != null) { // 当前节点存在数据
System.out.println(currentNode.getData()) ;
currentNode = currentNode.getNext() ; // 将下一个节点设置为当前节点
}
}
}public class LinkDemo {
public static void main(String args[]) {
// 第一步:定义要操作的节点并设置好包装的字符串数据
Node root = new Node("火车头") ; // 定义节点,同时包装数据
Node n1 = new Node("车厢A") ; // 定义节点,同时包装数据
Node n2 = new Node("车厢B") ; // 定义节点,同时包装数据
root.setNext(n1) ; // 设置节点关系
n1.setNext(n2) ; // 设置节点关系
// 第二步:根据节点关系取出所有数据
Node currentNode = root ; // 当前从根节点开始读取
while (currentNode != null) { // 当前节点存在数据
System.out.println(currentNode.getData()) ;
currentNode = currentNode.getNext() ; // 将下一个节点设置为当前节点
}
}
}本程序一共分为以下操作步骤进行。
- 第1步:定义各个独立的节点,同时封装要保存的字符串数据;
- 第2步:配置不同节点彼此间的操作关系;
- 第3步:由于现在不清楚要输出的节点个数,只知道输出的结束条件(没有节点就不输出了,currentNode == null),所以使用
while循环,依次取得每一个节点,并输出里面包装的数据。
虽然利用 while 循环可以轻松取得节点中包装的数据,但是这种输出操作本身并不是最理想的,而且与上图所示的输出原理也有差异,所以最合适的操作应该是采用 递归输出 。
public class LinkDemo {
public static void main(String args[]) {
// 第一步:定义要操作的节点并设置好包装的字符串数据
Node root = new Node("火车头") ; // 定义节点,同时包装数据
Node n1 = new Node("车厢A") ; // 定义节点,同时包装数据
Node n2 = new Node("车厢B") ; // 定义节点,同时包装数据
root.setNext(n1) ; // 设置节点关系
n1.setNext(n2) ; // 设置节点关系
print(root) ; // 由根节点开始输出
}
/**
* 利用递归方式输出所有的节点数据
* @param current
*/
public static void print(Node current) { // 第二步:根据节点关系取出所有数据
if (current == null) { // 递归结束条件
return; // 结束方法
}
System.out.println(current.getData()); // 输出节点包含的数据
print(current.getNext()); // 递归操作
}
}public class LinkDemo {
public static void main(String args[]) {
// 第一步:定义要操作的节点并设置好包装的字符串数据
Node root = new Node("火车头") ; // 定义节点,同时包装数据
Node n1 = new Node("车厢A") ; // 定义节点,同时包装数据
Node n2 = new Node("车厢B") ; // 定义节点,同时包装数据
root.setNext(n1) ; // 设置节点关系
n1.setNext(n2) ; // 设置节点关系
print(root) ; // 由根节点开始输出
}
/**
* 利用递归方式输出所有的节点数据
* @param current
*/
public static void print(Node current) { // 第二步:根据节点关系取出所有数据
if (current == null) { // 递归结束条件
return; // 结束方法
}
System.out.println(current.getData()); // 输出节点包含的数据
print(current.getNext()); // 递归操作
}
}本程序定义了一个 print() 方法实现节点数据的输出操作,在 print() 方法中会依照节点关系递归调用本方法,如果当前节点之后没有节点,将结束调用。
链表的基本雏形
通过上面的分析,可以发现链表实现中最为重要的类就是 Node ,而上一节的程序都是由用户自己使用 Node 类封装要操作的数据,同时由用户自己去匹配节点关系。很明显,这样会给用户操作带来更多的复杂性,而用户实际上只关心链表中保存的数据有哪些,至于说数据是如何保存的,节点间的关系是如何分配的,用户完全不需要知道。所以此时应该定义一个专门负责这个节点操作的类,而这个类可以称为链表操作类一 Link ,专门负责处理节点关系,用户不需要关心节点问题,只需要关心 Link 的处理操作即可。
为了帮助读者更好的理解 Node 类和 Link 类之间的联系,下面首先为读者做一个简单的代码模型,本代码的功能是通过 Link 类保存多个数据,然后由 Link 类自己去配置节点操作关系,最后将全部数据进行输出。本程序的操作流程如图所示。
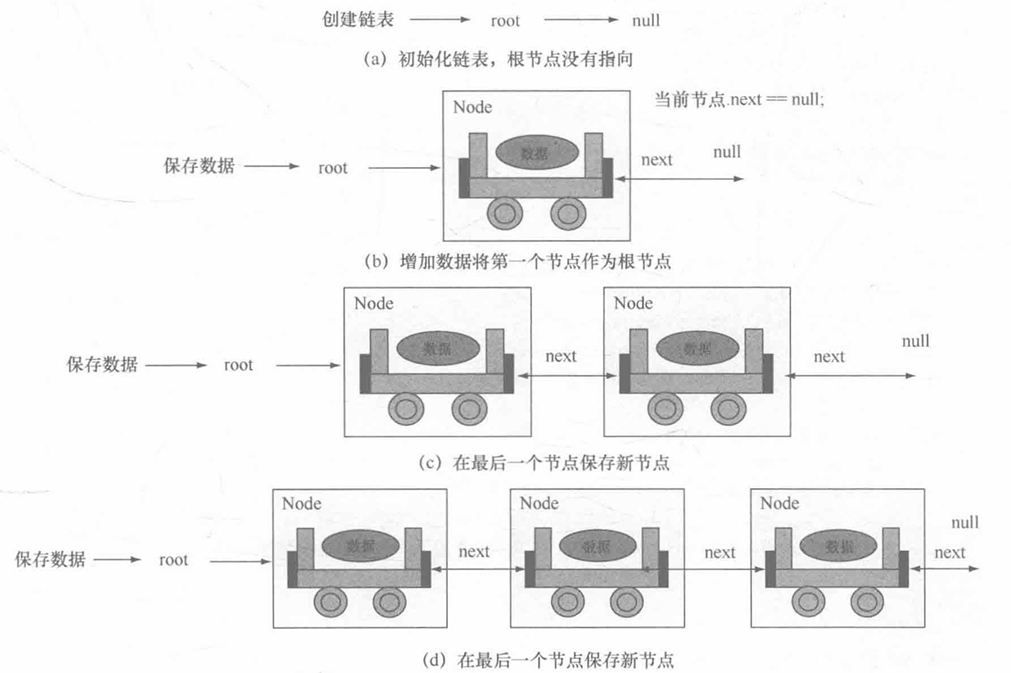
通过上图所示的操作图可以发现,如果要实现一个链表的操作,必须有一个 根节点 ,所有的节点都应该在根节点下依次保存。下面通过具体的代码实现此链表操作。
链表操作的标准形式结构
链表的基本操作有如下特点。
- 客户端代码不用关注具体的
Node以及引用关系的细节,只需要关注Link类中提供的数据操作方法; Link类的主要功能是控制Node类对象的产生和根节点;Node类主要负责数据的保存以及引用关系的分配。
class Node { // 定义一个节点
private String data; // 要保存的数据
private Node next; // 要保存的下一个节点
public Node(String data) { // 每一个Node类对象都必须保存相应的数据
this.data = data;
}
public void setNext(Node next) {
this.next = next;
}
public Node getNext() {
return this.next;
}
public String getData() {
return this.data;
}
/**
* 实现节点的添加(递归调用,目的是将新节点保存到最后一个节点之后)
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* 第三次调用(Node):this = Link.root.next.next
* @param newNode 新节点,节点对象由Link类创建
*/
public void addNode(Node newNode) {
if (this.next == null) { // 当前节点的下一个为null
this.next = newNode; // 保存新节点
} else { // 当前节点之后还存在节点
this.next.addNode(newNode); // 当前节点的下一个节点继续保存
}
}
/**
* 递归的方式输出每个节点保存的数据
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* 第三次调用(Node):this = Link.root.next.next
*/
public void printNode() {
System.out.println(this.data); // 输出当前节点数据
if (this.next != null) { // 还有下一个节点
this.next.printNode(); // 找到下一个节点继续输出
}
}
}
class Link { // 负责数据的设置和输出
private Node root; // 根节点
/**
* 向链表中增加新的数据,如果当前链表没有节点则将第一个数据作为节点
* 如果有节点则使用Node类将新节点保存到最后一个节点之后
* @param data 要保存的数据
*/
public void add(String data) {
Node newNode = new Node(data); // 设置数据的先后关系,所以将data包装在一个Node类对象中
if (this.root == null) { // 一个链表只有一个根节点
this.root = newNode; // 将新的节点设置为根节点
} else { // 根节点已经存在
this.root.addNode(newNode); // 交由Node类来进行节点保存
}
}
/**
* 使用递归方式,输出节点中的全部数据
*/
public void print() { // 输出数据
if (this.root != null) { // 存在根节点
this.root.printNode(); // 交给Node类输出
}
}
}
public class LinkDemo {
public static void main(String args[]) {
Link link = new Link(); // 由这个类负责所有的数据操作
link.add("Hello"); // 存放数据
link.add("MLDN"); // 存放数据
link.add("YOOTK"); // 存放数据
link.add("李兴华"); // 存放数据
link.print(); // 展示数据
}
}class Node { // 定义一个节点
private String data; // 要保存的数据
private Node next; // 要保存的下一个节点
public Node(String data) { // 每一个Node类对象都必须保存相应的数据
this.data = data;
}
public void setNext(Node next) {
this.next = next;
}
public Node getNext() {
return this.next;
}
public String getData() {
return this.data;
}
/**
* 实现节点的添加(递归调用,目的是将新节点保存到最后一个节点之后)
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* 第三次调用(Node):this = Link.root.next.next
* @param newNode 新节点,节点对象由Link类创建
*/
public void addNode(Node newNode) {
if (this.next == null) { // 当前节点的下一个为null
this.next = newNode; // 保存新节点
} else { // 当前节点之后还存在节点
this.next.addNode(newNode); // 当前节点的下一个节点继续保存
}
}
/**
* 递归的方式输出每个节点保存的数据
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* 第三次调用(Node):this = Link.root.next.next
*/
public void printNode() {
System.out.println(this.data); // 输出当前节点数据
if (this.next != null) { // 还有下一个节点
this.next.printNode(); // 找到下一个节点继续输出
}
}
}
class Link { // 负责数据的设置和输出
private Node root; // 根节点
/**
* 向链表中增加新的数据,如果当前链表没有节点则将第一个数据作为节点
* 如果有节点则使用Node类将新节点保存到最后一个节点之后
* @param data 要保存的数据
*/
public void add(String data) {
Node newNode = new Node(data); // 设置数据的先后关系,所以将data包装在一个Node类对象中
if (this.root == null) { // 一个链表只有一个根节点
this.root = newNode; // 将新的节点设置为根节点
} else { // 根节点已经存在
this.root.addNode(newNode); // 交由Node类来进行节点保存
}
}
/**
* 使用递归方式,输出节点中的全部数据
*/
public void print() { // 输出数据
if (this.root != null) { // 存在根节点
this.root.printNode(); // 交给Node类输出
}
}
}
public class LinkDemo {
public static void main(String args[]) {
Link link = new Link(); // 由这个类负责所有的数据操作
link.add("Hello"); // 存放数据
link.add("MLDN"); // 存放数据
link.add("YOOTK"); // 存放数据
link.add("李兴华"); // 存放数据
link.print(); // 展示数据
}
}本程序将节点的匹配关系交由 Node 类来进行处理,而数据的节点包装以及根节点的管理交由 Link 类负责管理,这样用户在使用链表操作时不需要关注 Node 类的操作,只需要通过 Link 类的 add() 方法实现数据增加,通过 print() 方法实现数据输出。
开发可用链表
上一节的程序代码已经实现了链表的基本操作,但是读者应该会发现一个问题,在进行链表数据取出时不应该采用直接输出的方式完成,而是应该 将数据返回给调用处完成 。所以之前的链表只是为读者提供了一个基础的开发模型,并不能用于实际的开发中,而如果要想让链表真正可以使用,就应该具备下表所示的操作功能。
| No. | 方法名称 | 类型 | 描述 |
|---|---|---|---|
| 1 | public void add(数据类型变量) | 普通 | 向链表中增加新的数据 |
| 2 | public int size() | 普通 | 取得链表中保存的元素个数 |
| 3 | public boolean isEmpty() | 普通 | 判断是否是空链表(size0==0) |
| 4 | public boolean contains(数据类型变量) | 普通 | 判断某一个数据是否存在 |
| 5 | public数据类型get(int index) | 普通 | 根据索引取得数据 |
| 6 | publicvoid set(int index,数据类型变量) | 普通 | 使用新的内容替换指定索引的旧内容 |
| 7 | public void remove(数据类型 变量) | 普通 | 删除指定数据,如果是对象则要进行对象 比较 |
| 8 | public数据类型 toArray() | 普通 | 将链表以对象数组的形式返回 |
| 9 | public void clear() | 普通 | 清空链表 |
通过表列出的方法,读者可以发现,链表的主要操作就是数据的 增加、修改、删除、查询 4 个基本操作。下面依次来观察每个方法的具体实现原理。
程序基本结构
在开发具体的可用链表操作之前,首先必须明确一个道理:Node 类负责所有的节点数据的保存以及节点关系的匹配,所以 Node 类不可能单独去使用。但范例的代码实现过程中 Node 是可以单独使用的,外部程序可以绕过 Link 类直接操作 Node 类,这明显是没有任何意义的。所以下面必须修改设计结构,让 Node 类 只能 被 Link 类使用。
使用内部类明显是一个最好的选择。一方面,内部类可以使用 private 定义,这样一个内部类只能被一个外部类使用。另一方面,内部类可以方便地与外部类之间进行私有属性的直接访问。
class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private String data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(String data) { // 每一个Node类对象都必须保存相应的数据
this.data = data;
}
}
// ===================== 以上为内部类 ===================
private Node root; // 根节点定义
}class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private String data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(String data) { // 每一个Node类对象都必须保存相应的数据
this.data = data;
}
}
// ===================== 以上为内部类 ===================
private Node root; // 根节点定义
}在本程序中将 Node 定义为 Link 的私有内部类,这样做有以下两个好处。
Node类只为Link类服务,并且可以利用Node类匹配节点关系;- 外部类与内部类之间方便进行私有属性的直接访问,所以不需要在
Node类中定义setter、getter方法。
数据增加:public void add(数据类型变量)
如果要进行新数据的增加,则应该由 Link 类负责节点对象的产生,并且由 Link 类维护根节点,所有节点的关系匹配交给 Node 类处理
class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private String data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(String data) { // 每一个 Node 类对象都必须保存相应的数据
this.data = data;
}
/**
* 设置新节点的保存,所有的新节点保存在最后一个节点之后
*
* @param newNode 新节点
*/
public void addNode(Node newNode) {
if (this.next == null) { // 当前的下一个节点为null
this.next = newNode; // 保存节点
} else { // 继续向后保存
this.next.addNode(newNode);
}
}
}
public Node root; // 根节点定义
/**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺
*
* @param data 数据
*/
public void add(String data) {
if (data == null) {
return;
}
Node newNode = new Node(data);
if (this.root == null) {
this.root = newNode;
} else {
this.root.addNode(newNode);
}
}
}
public class LinkDemo {
public static void main(String[] args) {
Link all = new Link();
all.add("java");
all.add("python");
all.add(null);
}
}class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private String data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(String data) { // 每一个 Node 类对象都必须保存相应的数据
this.data = data;
}
/**
* 设置新节点的保存,所有的新节点保存在最后一个节点之后
*
* @param newNode 新节点
*/
public void addNode(Node newNode) {
if (this.next == null) { // 当前的下一个节点为null
this.next = newNode; // 保存节点
} else { // 继续向后保存
this.next.addNode(newNode);
}
}
}
public Node root; // 根节点定义
/**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺
*
* @param data 数据
*/
public void add(String data) {
if (data == null) {
return;
}
Node newNode = new Node(data);
if (this.root == null) {
this.root = newNode;
} else {
this.root.addNode(newNode);
}
}
}
public class LinkDemo {
public static void main(String[] args) {
Link all = new Link();
all.add("java");
all.add("python");
all.add(null);
}
}数据的增加操作实现过程与之前讲解的区别不大,其中用户首先通过 Link 类的 add() 方法保存数据,而在 add() 方法中会创建新的节点,然后利用 Node 类的 addNode() 方法匹配节点关系。
取得保存元素个数:public int size()
既然每一个链表对象都只有一个 root 根元素,那么每一个链表就有自己的长度,可以直接在 Link 类里面设置一个 count 属性,每一次数据添加完成后,可以进行个数的自增。
- 增加一个
count属性,保存元素个数;
private int count = 0 ; private int count = 0 ;- 在
add()方法里面增加数据的统计操作;
/**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺序
* @param data 要保存的数据
*/
public void add(String data) { // 假设不允许有null
if (data == null) { // 判断数据是否为空
return; // 结束方法调用
}
Node newNode = new Node(data); // 要保存的数据
if (this.root == null) { // 当前没有根节点
this.root = newNode; // 保存根节点
} else { // 根节点存在
this.root.addNode(newNode); // 交给Node类处理节点的保存
}
this.count ++ ; // 数据保存成功后保存个数加一
} /**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺序
* @param data 要保存的数据
*/
public void add(String data) { // 假设不允许有null
if (data == null) { // 判断数据是否为空
return; // 结束方法调用
}
Node newNode = new Node(data); // 要保存的数据
if (this.root == null) { // 当前没有根节点
this.root = newNode; // 保存根节点
} else { // 根节点存在
this.root.addNode(newNode); // 交给Node类处理节点的保存
}
this.count ++ ; // 数据保存成功后保存个数加一
}- 随后为
Link类增加一个新的方法:size()。
/**
* 取得链表中保存的数据个数
* @return 保存的个数,通过count属性取得
*/
public int size() { // 取得保存的数据量
return this.count;
} /**
* 取得链表中保存的数据个数
* @return 保存的个数,通过count属性取得
*/
public int size() { // 取得保存的数据量
return this.count;
}在 Link 类中定义的 size() 方法并不需要做过多的复杂操作,只需要返回 count 属性的内容即可。
判断是否是空链表:public boolean isEmpty()
所谓空链表(不是null)指的是链表中 不保存任何数据 。空链表的判断实际上可以通过以下两种方式完成。
- 第一种:判断
root是否有对象(是否为null); - 第二种:判断保存的数据量(count)。
/**
* 判断是否是空链表,表示长度为0,不是null
* @return 如果链表中没有保存任何数据则返回true,否则返回false
*/
public boolean isEmpty() {
return this.count == 0;
} /**
* 判断是否是空链表,表示长度为0,不是null
* @return 如果链表中没有保存任何数据则返回true,否则返回false
*/
public boolean isEmpty() {
return this.count == 0;
}本程序直接利用 count 属性进行了判断,如果没有保存过数据,则 count 属性的内容就是其默认值 0 ,那么 isEmpty() 方法返回的就是 true ,反之则为 false 。
public boolean contains(数据类型变量)
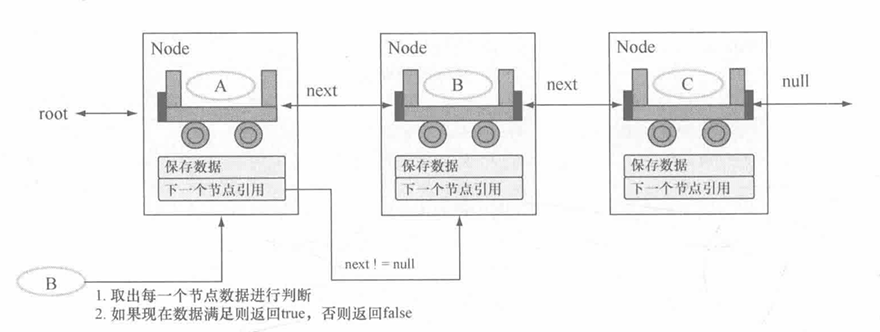
在链表中一定会保存多个数据,那么基本的判断数据是否存在的方式是:以 String 为例(equals() 方法判断),在判断一个字符串是否存在时,需要循环链表中的全部内容,并且与要查询的数据进行匹配,如果查找到了则返回 true ,否则返回 false 。其实现原理如图所示。
/**
* 数据检索操作,判断指定数据是否存在
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* @param data 要查询的数据
* @return 如果数据存在返回true,否则返回false
*/
public boolean containsNode(String data) {
if (data.equals(this.data)) { // 当前节点数据为要查询的数据
return true; // 后面不再查询
} else { // 当前节点数据不满足查询要求
if (this.next != null) { // 有后续节点
return this.next.containsNode(data); // 递归调用继续查询
} else { // 没有后续节点
return false; // 没有查询到返回false
}
} /**
* 数据检索操作,判断指定数据是否存在
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* @param data 要查询的数据
* @return 如果数据存在返回true,否则返回false
*/
public boolean containsNode(String data) {
if (data.equals(this.data)) { // 当前节点数据为要查询的数据
return true; // 后面不再查询
} else { // 当前节点数据不满足查询要求
if (this.next != null) { // 有后续节点
return this.next.containsNode(data); // 递归调用继续查询
} else { // 没有后续节点
return false; // 没有查询到返回false
}
} /**
* 数据查询操作,判断指定数据是否存在,如果链表没有数据直接返回false
* @param data 要判断的数据
* @return 数据存在返回true,否则返回false
*/
public boolean contains(String data) {
if (data == null || this.root == null) { // 现在没有要查询的数据,根节点也不保存数据
return false ; // 没有查询结果
}
return this.root.containsNode(data) ; // 交由Node类查询
} /**
* 数据查询操作,判断指定数据是否存在,如果链表没有数据直接返回false
* @param data 要判断的数据
* @return 数据存在返回true,否则返回false
*/
public boolean contains(String data) {
if (data == null || this.root == null) { // 现在没有要查询的数据,根节点也不保存数据
return false ; // 没有查询结果
}
return this.root.containsNode(data) ; // 交由Node类查询
}本程序从根元素开始查询数据是否存在。
public class LinkDemo {
public static void main(String args[]) {
Link all = new Link(); // 创建链表对象
all.add("yootk"); // 保存数据
all.add("mldn"); // 保存数据
System.out.println(all.contains("yootk")) ;
System.out.println(all.contains("hello")) ;
}
}public class LinkDemo {
public static void main(String args[]) {
Link all = new Link(); // 创建链表对象
all.add("yootk"); // 保存数据
all.add("mldn"); // 保存数据
System.out.println(all.contains("yootk")) ;
System.out.println(all.contains("hello")) ;
}
}本程序在链表中会进行是否存在数据的判断,如果没有数据存在则返回 false (数据没有查询到),否则返回 true (数据查询到)。本程序使用的是 String 型数据,所以在 Node 类中判断数据是否存在时使用的是 equals() 方法。
自定义对象时需要改变方法
在链表中并不一定只能保存 String 型数据,任何对象都可以进行保存,如果要保存的是一个自定义的 Book 类,则必须在 Book 类中编写相应的对象比较方法(暂定方法为 compare() )。所以读者一定要记住一个结论: 数据是否存在的判断必须有对象比较操作的支持。
根据索引取得数据:public 数据类型 get(int index)
链表本身就属于一种 动态的对象数组 ,与普通的对象数组相比,链表最大的优势就在于 没有长度限制 。那么既然链表属于动态对象数组,也就应该具备像数组那样可以根据索引取得元素的功能,自然也就能根据指定索引取得指定节点数据的操作。索引查询的操作原理如图所示。
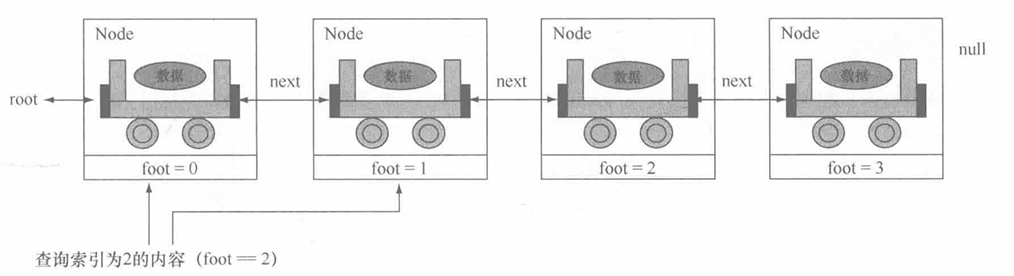
从图中可以发现,如果要想成功地为每一个保存的元素设置索引编号,一定需要一个变量(假设为foot)动态生成索引,考虑到所有的节点都被 Link 类所管理,所以可以在 Link 类中定义一个 foot 属性(内部类可以方便地访问外部类私有属性),这样只需要采用递归的方式依次生成索引,就可以取出指定索引的数据。
在 Link 类里面增加一个 foot 的属性,表示每一个 Node 元素的编号
private int foot = 0 ; // 节点索引private int foot = 0 ; // 节点索引在每一次查询时(一个链表可能查询多次),foot 应该都从头开始计算(foot设为0)。
/**
* 根据索引取得保存的节点数据
* @param index 索引数据
* @return 如果要取得的索引内容不存在或者大于保存个数返回null,反之返回数据
*/
public String get(int index) {
if (index > this.count) { // 超过了查询范围
return null ; // 没有数据
}
this.foot = 0 ; // 表示从前向后查询
return this.root.getNode(index) ; // 查询过程交给Node类
} /**
* 根据索引取得保存的节点数据
* @param index 索引数据
* @return 如果要取得的索引内容不存在或者大于保存个数返回null,反之返回数据
*/
public String get(int index) {
if (index > this.count) { // 超过了查询范围
return null ; // 没有数据
}
this.foot = 0 ; // 表示从前向后查询
return this.root.getNode(index) ; // 查询过程交给Node类
}在 Node 类里面实现 getNode() 方法,内部类和外部类之间可以方便地进行私有属性的互相访问。
/**
* 根据索引取出数据,此时该索引一定是存在的
* @param index 要取得数据的索引编号
* @return 返回指定索引节点包含的数据
*/
public String getNode(int index) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要查询的索引
return this.data; // 返回当前节点数据
} else { // 继续向后查询
return this.next.getNode(index); // 进行下一个节点的判断
}
} /**
* 根据索引取出数据,此时该索引一定是存在的
* @param index 要取得数据的索引编号
* @return 返回指定索引节点包含的数据
*/
public String getNode(int index) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要查询的索引
return this.data; // 返回当前节点数据
} else { // 继续向后查询
return this.next.getNode(index); // 进行下一个节点的判断
}
}在进行索引数据检索时首先会利用 Link 类的 get() 方法判断要取得的索引值是否超过了数据长度,如果没有超过,则交由 Node 类的 getNode() 方法处理,采用递归的方式进行索引的判断。
当链表中可以根据索引操作时,实际上也就意味着与数组的联系更加紧密了。
修改指定索引内容:public void set(int index,数据类型变量)
修改数据和查询的区别不大,查询数据当满足索引值时,只是进行了一个数据的返回,而修改数据只需要将数据返回变为数据的重新赋值即可。
/**
* 修改指定索引节点包含的数据
* @param index 要修改的索引编号
* @param data 新数据
*/
public void setNode(int index, String data) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要修改的索引
this.data = data; // 进行内容的修改
} else {
this.next.setNode(index, data); // 继续下一个节点的索引判断
}
} /**
* 修改指定索引节点包含的数据
* @param index 要修改的索引编号
* @param data 新数据
*/
public void setNode(int index, String data) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要修改的索引
this.data = data; // 进行内容的修改
} else {
this.next.setNode(index, data); // 继续下一个节点的索引判断
}
}修改之后由于索引都是动态生成的,所以取出数据的时候没有任何区别。
/**
* 根据索引修改数据
* @param index 要修改数据的索引编号
* @param data 新的数据内容
*/
public void set(int index, String data) {
if (index > this.count) { // 判断是否超过了保存范围
return; // 结束方法调用
}
this.foot = 0; // 重新设置foot属性的内容,作为索引出现
this.root.setNode(index, data); // 交给Node类设置数据内容
} /**
* 根据索引修改数据
* @param index 要修改数据的索引编号
* @param data 新的数据内容
*/
public void set(int index, String data) {
if (index > this.count) { // 判断是否超过了保存范围
return; // 结束方法调用
}
this.foot = 0; // 重新设置foot属性的内容,作为索引出现
this.root.setNode(index, data); // 交给Node类设置数据内容
}本程序采用与 get() 方法类似的做法,唯一的区别是,在 Node 类中定义 setNode() 方法不再返回数据,而是直接修改了满足指定索引的节点数据。
数据删除:public void remove(数据类型变量)
对于链表中的内容,前几节完成的是增加操作和查询操作,但是链表中也会存在删除数据的操作。删除数据的操作需要分以下两种情况讨论。
- 情况一:要删除的数据是根节点,则
root应该变为根节点.next(根节点的下一个节点为新的根节点) ,并且由于根节点需要被Link类所指,所以此种情况要在Link类中进行处理,如图所示。
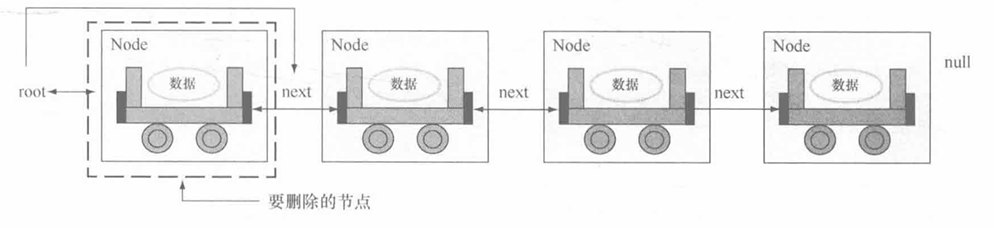
- 情况二:要删除的不是根节点,而是其他普通节点。这时删除节点的操作应该放在
Node类里处理,并且由于Link类已经判断过根节点,所以此处应该从第二个节点开始判断的,如图所示。
通过分析可以得出删除数据的最终的形式:当前节点上一节点.next = 当前节点.next ,即空出当前引用节点。
/**
* 节点的删除操作,匹配每一个节点的数据,如果当前节点数据符合删除数据
* 则使用“当前节点上一节点.next = 当前节点.next”方式空出当前节点
* 第一次调用(Link): previous = Link.root、this = Link.root.next
* 第二次调用(Node): previous = Link.root.next、this = Link.root.next.next
* @param previous 当前节点的上一个节点
* @param data 要删除的数据
*/
public void removeNode(Node previous, String data) {
if (data.equals(this.data)) { // 当前节点为要删除节点
previous.next = this.next; // 空出当前节点
} else { // 应该向后继续查询
this.next.removeNode(this, data); // 继续下一个判断
}
} /**
* 节点的删除操作,匹配每一个节点的数据,如果当前节点数据符合删除数据
* 则使用“当前节点上一节点.next = 当前节点.next”方式空出当前节点
* 第一次调用(Link): previous = Link.root、this = Link.root.next
* 第二次调用(Node): previous = Link.root.next、this = Link.root.next.next
* @param previous 当前节点的上一个节点
* @param data 要删除的数据
*/
public void removeNode(Node previous, String data) {
if (data.equals(this.data)) { // 当前节点为要删除节点
previous.next = this.next; // 空出当前节点
} else { // 应该向后继续查询
this.next.removeNode(this, data); // 继续下一个判断
}
} /**
* 链表数据的删除操作,在删除前要先使用contains()判断链表中是否存在指定数据
* 如果要删除的数据存在,则首先判断根节点的数据是否为要删除数据
* 如果是,则将根节点的下一个节点作为新的根节点
* 如果要删除的数据不是根节点数据,则将删除操作交由Node类的removeNode()方法完成
* @param data 要删除的数据
*/
public void remove(String data) {
if (this.contains(data)) { // 主要功能是判断数据是否存在
// 要删除数据是否是根节点数据,root是Node类的对象,此处直接访问内部类的私有操作
if (data.equals(this.root.data)) { // 根节点数据为要删除数据
this.root = this.root.next; // 空出当前根节点
} else { // 根节点数据不是要删除数据
// 此时根元素已经判断过了,从第二个元素开始判断,即第二个元素的上一个元素为根节点
this.root.next.removeNode(this.root, data);
}
this.count--; // 删除成功后个数要减少
}
} /**
* 链表数据的删除操作,在删除前要先使用contains()判断链表中是否存在指定数据
* 如果要删除的数据存在,则首先判断根节点的数据是否为要删除数据
* 如果是,则将根节点的下一个节点作为新的根节点
* 如果要删除的数据不是根节点数据,则将删除操作交由Node类的removeNode()方法完成
* @param data 要删除的数据
*/
public void remove(String data) {
if (this.contains(data)) { // 主要功能是判断数据是否存在
// 要删除数据是否是根节点数据,root是Node类的对象,此处直接访问内部类的私有操作
if (data.equals(this.root.data)) { // 根节点数据为要删除数据
this.root = this.root.next; // 空出当前根节点
} else { // 根节点数据不是要删除数据
// 此时根元素已经判断过了,从第二个元素开始判断,即第二个元素的上一个元素为根节点
this.root.next.removeNode(this.root, data);
}
this.count--; // 删除成功后个数要减少
}
}在本程序中 Link 类负责根节点的删除判断,而 Node 类的删除判断从第二个节点开始,而删除的控制方法就是空出一个对象,使其成为垃圾空间。
将链表变为对象数组:public 数据类型 toArray()
对于链表的这种数据结构,在实际的开发中,最为关键的两个操作是:增加数据和取得全部数据。而链表本身属于一种动态的对象数组,所以在链表输出时,最好的做法是将链表中所保存的数据以对象数组的方式返回,而返回对象的数组长度也应该是根据保存数据的个数决定的。其操作原理如图所示。
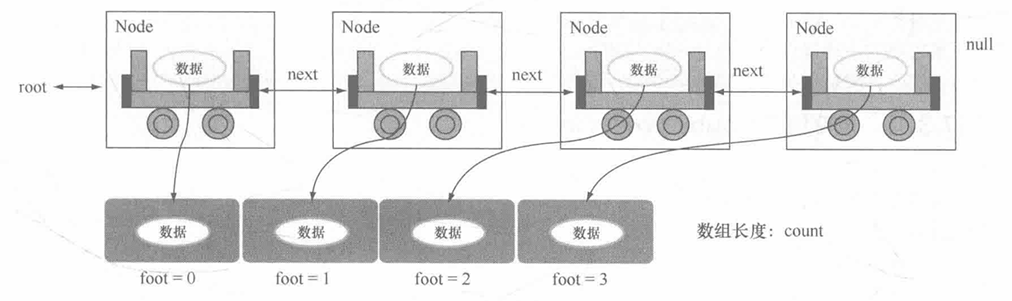
通过以上分析发现,最终 Link 类的 toArray() 方法一定要返回一个对象数组,数组的长度由 Link 类中的 count 属性决定,并且这个对象数组的内容需要由 Node 类负责填充,所以这个对象数组最好定义在 Link 类的属性里面。
- 增加一个返回的数组属性内容,之所以将其定义为属性,是因为内部类和外部类都可以访问;
private String [] retArray ; // 返回的数组 private String [] retArray ; // 返回的数组- 增加
toArray()方法
/**
* 将链表中的数据转换为对象数组输出
* @return 如果链表没有数据返回null,如果有数据则将数据变为对象数组后返回
*/
public String[] toArray() {
if (this.root == null) { // 判断链表是否有数据
return null; // 没有数据返回null
}
this.foot = 0; // 脚标清零操作
this.retArray = new String[this.count]; // 根据保存内容开辟数组
this.root.toArrayNode(); // 交给Node类处理
return this.retArray; // 返回数组对象
} /**
* 将链表中的数据转换为对象数组输出
* @return 如果链表没有数据返回null,如果有数据则将数据变为对象数组后返回
*/
public String[] toArray() {
if (this.root == null) { // 判断链表是否有数据
return null; // 没有数据返回null
}
this.foot = 0; // 脚标清零操作
this.retArray = new String[this.count]; // 根据保存内容开辟数组
this.root.toArrayNode(); // 交给Node类处理
return this.retArray; // 返回数组对象
}在 Node 类里面处理数组数据的保存。
/**
* 将节点中保存的内容转化为对象数组
* 第一次调用(Link):this = Link.root;
* 第二次调用(Node):this = Link.root.next
*/
public void toArrayNode() {
Link.this.retArray[Link.this.foot++] = this.data; // 取出数据并保存在数组中
if (this.next != null) { // 有后续元素
this.next.toArrayNode(); // 继续下一个数据的取得
}
} /**
* 将节点中保存的内容转化为对象数组
* 第一次调用(Link):this = Link.root;
* 第二次调用(Node):this = Link.root.next
*/
public void toArrayNode() {
Link.this.retArray[Link.this.foot++] = this.data; // 取出数据并保存在数组中
if (this.next != null) { // 有后续元素
this.next.toArrayNode(); // 继续下一个数据的取得
}
}本程序的主要操作都是由 Node 类的 toArrayNode() 递归操作完成的,在 Link 类的 toArray() 万法中会根据保存的数据长度开辟数组空间,将数组内容填充完毕后会返回给调用处。
清空链表:public void clear()
所有的链表被 root 引用,这时如果 root 为 null ,那么后面的数据都会断开,就表示都成了垃圾。
public void clear() {
this.root = null; // 清空链表
this.count = 0; // 元素个数为0
} public void clear() {
this.root = null; // 清空链表
this.count = 0; // 元素个数为0
}本程序除了将根节点清空外,也将对象的保存个数进行清零操作,以方便新数据的保存。
使用链表
上一节给出的链表严格来讲不够实用,而且意义也不大,因为它所能操作的数据类型只有 String ,毕竟 String 所保留的数据比较少。下面进一步提升,采用自定义类来进行链表的操作。
通过链表的分析可以发现,在链表操作中如果要想正常执行 cotains() 、 remove() 等功能,则类中必须要提供对象比较方法的支持,此处的对象比较操作方法依然是用 compare() 作为方法名称。
class Book {
private String title ;
private double price ;
public Book(String title,double price) {
this.title = title ;
this.price = price ;
}
/**
* 进行本类对象的比较操作,在比较过程中首先会判断传入的对象是否为null,而后判断地址是否相同
* 如果都不相同则进行对象内容的判断,由于compare()方法接收了本类引用,所以可以直接访问私有属性
* @param book 要进行判断的数据
* @return 内存地址相同或属性完全相同返回true,否则返回false
*/
public boolean compare(Book book) {
if (book == null) { // 传入数据为null
return false ; // 没有必要进行具体的判断
}
// 执行“b1.compare(b2)”代码时会有两个对象
// 当前对象this(调用方法对象,就是b1引用)
// 传递的对象book(引用传递,就是b2引用)
if (this == book) { // 内存地址相同
return true ; // 避免进行具体细节的比较,节约时间
}
if (this.title.equals(book.title)
&& this.price == book.price) { // 属性判断
return true ;
} else {
return false ;
}
}
// setter、getter略
public String getInfo() {
return "图书名称:" + this.title + ",图书价格:" + this.price ;
}
}class Book {
private String title ;
private double price ;
public Book(String title,double price) {
this.title = title ;
this.price = price ;
}
/**
* 进行本类对象的比较操作,在比较过程中首先会判断传入的对象是否为null,而后判断地址是否相同
* 如果都不相同则进行对象内容的判断,由于compare()方法接收了本类引用,所以可以直接访问私有属性
* @param book 要进行判断的数据
* @return 内存地址相同或属性完全相同返回true,否则返回false
*/
public boolean compare(Book book) {
if (book == null) { // 传入数据为null
return false ; // 没有必要进行具体的判断
}
// 执行“b1.compare(b2)”代码时会有两个对象
// 当前对象this(调用方法对象,就是b1引用)
// 传递的对象book(引用传递,就是b2引用)
if (this == book) { // 内存地址相同
return true ; // 避免进行具体细节的比较,节约时间
}
if (this.title.equals(book.title)
&& this.price == book.price) { // 属性判断
return true ;
} else {
return false ;
}
}
// setter、getter略
public String getInfo() {
return "图书名称:" + this.title + ",图书价格:" + this.price ;
}
}本程序首先按照对象比较的要求定义了 compare() 方法,然后如果要在链表中保存此类型,则必须将链表中操作的 String 数据类型全部替换为 Book 类型。
class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private Book data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(Book data) { // 每一个Node类对象都必须保存相应的数据
this.data = data;
}
/**
* 设置新节点的保存,所有的新节点保存在最后一个节点之后
* @param newNode 新节点对象
*/
public void addNode(Node newNode) {
if (this.next == null) { // 当前的下一个节点为null
this.next = newNode ; // 保存节点
} else { // 向后继续保存
this.next.addNode(newNode) ;
}
}
/**
* 数据检索操作,判断指定数据是否存在
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* @param data 要查询的数据
* @return 如果数据存在返回true,否则返回false
*/
public boolean containsNode(Book data) {
if (data.compare(this.data)) { // 当前节点数据为要查询的数据
return true; // 后面不再查询了
} else { // 当前节点数据不满足查询要求
if (this.next != null) { // 有后续节点
return this.next.containsNode(data); // 递归调用继续查询
} else { // 没有后续节点
return false; // 没有查询到返回false
}
}
}
/**
* 根据索引取出数据,此时该索引一定是存在的
* @param index 要取得数据的索引编号
* @return 返回指定索引节点包含的数据
*/
public Book getNode(int index) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要查询的索引
return this.data; // 返回当前节点数据
} else { // 继续向后查询
return this.next.getNode(index); // 进行下一个节点的判断
}
}
/**
* 修改指定索引节点包含的数据
* @param index 要修改的索引编号
* @param data 新数据
*/
public void setNode(int index, Book data) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要修改的索引
this.data = data; // 进行内容的修改
} else {
this.next.setNode(index, data); // 继续下一个节点的索引判断
}
}
/**
* 节点的删除操作,匹配每一个节点的数据,如果当前节点数据符合删除数据,
* 则使用“当前节点上一节点.next = 当前节点.next”方式空出当前节点
* 第一次调用(Link):previous = Link.root、this = Link.root.next
* 第二次调用(Node):previous = Link.root.next、this = Link.root.next.next
* @param previous 当前节点的上一个节点
* @param data 要删除的数据
*/
public void removeNode(Node previous, Book data) {
if (data.compare(this.data)) { // 当前节点为要删除节点
previous.next = this.next; // 空出当前节点
} else { // 应该向后继续查询
this.next.removeNode(this, data); // 继续下一个判断
}
}
/**
* 将节点中保存的内容转化为对象数组
* 第一次调用(Link):this = Link.root;
* 第二次调用(Node):this = Link.root.next;
*/
public void toArrayNode() {
Link.this.retArray[Link.this.foot++] = this.data; // 取出数据并保存在数组中
if (this.next != null) { // 有后续元素
this.next.toArrayNode(); // 继续下一个数据的取得
}
}
}
// ===================== 以上为内部类 ===================
private Node root; // 根节点定义
private int count = 0 ; // 保存元素的个数
private int foot = 0 ; // 节点索引
private Book [] retArray ; // 返回的数组
/**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺序
* @param data 要保存的数据
*/
public void add(Book data) { // 假设不允许有null
if (data == null) { // 判断数据是否为空
return; // 结束方法调用
}
Node newNode = new Node(data); // 要保存的数据
if (this.root == null) { // 当前没有根节点
this.root = newNode; // 保存根节点
} else { // 根节点存在
this.root.addNode(newNode); // 交给Node类处理节点的保存
}
this.count ++ ; // 数据保存成功后保存个数加一
}
/**
* 取得链表中保存的数据个数
* @return 保存的个数,通过count属性取得
*/
public int size() { // 取得保存的数据量
return this.count;
}
/**
* 判断是否是空链表,表示长度为0,不是null
* @return 如果链表中没有保存任何数据则返回true,否则返回false
*/
public boolean isEmpty() {
return this.count == 0;
}
/**
* 数据查询操作,判断指定数据是否存在,如果链表没有数据直接返回false
* @param data 要判断的数据
* @return 数据存在返回true,否则返回false
*/
public boolean contains(Book data) {
if (data == null || this.root == null) { // 现在没有要查询的数据,根节点也不保存数据
return false ; // 没有查询结果
}
return this.root.containsNode(data) ; // 交由Node类查询
}
/**
* 根据索引取得保存的节点数据
* @param index 索引数据
* @return 如果要取得的索引内容不存在或者大于保存个数返回null,反之返回数据
*/
public Book get(int index) {
if (index > this.count) { // 超过了查询范围
return null ; // 没有数据
}
this.foot = 0 ; // 表示从前向后查询
return this.root.getNode(index) ; // 查询过程交给Node类
}
/**
* 根据索引修改数据
* @param index 要修改数据的索引编号
* @param data 新的数据内容
*/
public void set(int index, Book data) {
if (index > this.count) { // 判断是否超过了保存范围
return; // 结束方法调用
}
this.foot = 0; // 重新设置foot属性的内容,作为索引出现
this.root.setNode(index, data); // 交给Node类设置数据内容
}
/**
* 链表数据的删除操作,在删除前要先使用contains()判断链表中是否存在指定数据
* 如果要删除的数据存在,则首先判断根节点的数据是否为要删除数据
* 如果是,则将根节点的下一个节点作为新的根节点
* 如果要删除的数据不是根节点数据,则将删除操作交由Node类的removeNode()方法完成
* @param data 要删除的数据
*/
public void remove(Book data) {
if (this.contains(data)) { // 主要功能是判断数据是否存在
// 要删除数据是否是根节点数据,root是Node类的对象,此处直接访问内部类的私有操作
if (data.equals(this.root.data)) { // 根节点数据为要删除数据
this.root = this.root.next; // 空出当前根节点
} else { // 根节点数据不是要删除数据
// 此时根元素已经判断过了,从第二个元素开始判断,即第二个元素的上一个元素为根节点
this.root.next.removeNode(this.root, data);
}
this.count--; // 删除成功后个数要减少
}
}
/**
* 将链表中的数据转换为对象数组输出
* @return 如果链表没有数据返回null,如果有数据则将数据变为对象数组后返回
*/
public Book[] toArray() {
if (this.root == null) { // 判断链表是否有数据
return null; // 没有数据返回null
}
this.foot = 0; // 脚标清零操作
this.retArray = new Book[this.count]; // 根据保存内容开辟数组
this.root.toArrayNode(); // 交给Node类处理
return this.retArray; // 返回数组对象
}
public void clear() {
this.root = null; // 清空链表
this.count = 0; // 元素个数为0
}
}class Link { // 链表类,外部能够看见的只有这一个类
private class Node { // 定义的内部节点类
private Book data; // 要保存的数据
private Node next; // 下一个节点引用
public Node(Book data) { // 每一个Node类对象都必须保存相应的数据
this.data = data;
}
/**
* 设置新节点的保存,所有的新节点保存在最后一个节点之后
* @param newNode 新节点对象
*/
public void addNode(Node newNode) {
if (this.next == null) { // 当前的下一个节点为null
this.next = newNode ; // 保存节点
} else { // 向后继续保存
this.next.addNode(newNode) ;
}
}
/**
* 数据检索操作,判断指定数据是否存在
* 第一次调用(Link):this = Link.root
* 第二次调用(Node):this = Link.root.next
* @param data 要查询的数据
* @return 如果数据存在返回true,否则返回false
*/
public boolean containsNode(Book data) {
if (data.compare(this.data)) { // 当前节点数据为要查询的数据
return true; // 后面不再查询了
} else { // 当前节点数据不满足查询要求
if (this.next != null) { // 有后续节点
return this.next.containsNode(data); // 递归调用继续查询
} else { // 没有后续节点
return false; // 没有查询到返回false
}
}
}
/**
* 根据索引取出数据,此时该索引一定是存在的
* @param index 要取得数据的索引编号
* @return 返回指定索引节点包含的数据
*/
public Book getNode(int index) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要查询的索引
return this.data; // 返回当前节点数据
} else { // 继续向后查询
return this.next.getNode(index); // 进行下一个节点的判断
}
}
/**
* 修改指定索引节点包含的数据
* @param index 要修改的索引编号
* @param data 新数据
*/
public void setNode(int index, Book data) {
// 使用当前的foot内容与要查询的索引进行比较,随后将foot的内容自增,目的是下次查询方便
if (Link.this.foot++ == index) { // 当前为要修改的索引
this.data = data; // 进行内容的修改
} else {
this.next.setNode(index, data); // 继续下一个节点的索引判断
}
}
/**
* 节点的删除操作,匹配每一个节点的数据,如果当前节点数据符合删除数据,
* 则使用“当前节点上一节点.next = 当前节点.next”方式空出当前节点
* 第一次调用(Link):previous = Link.root、this = Link.root.next
* 第二次调用(Node):previous = Link.root.next、this = Link.root.next.next
* @param previous 当前节点的上一个节点
* @param data 要删除的数据
*/
public void removeNode(Node previous, Book data) {
if (data.compare(this.data)) { // 当前节点为要删除节点
previous.next = this.next; // 空出当前节点
} else { // 应该向后继续查询
this.next.removeNode(this, data); // 继续下一个判断
}
}
/**
* 将节点中保存的内容转化为对象数组
* 第一次调用(Link):this = Link.root;
* 第二次调用(Node):this = Link.root.next;
*/
public void toArrayNode() {
Link.this.retArray[Link.this.foot++] = this.data; // 取出数据并保存在数组中
if (this.next != null) { // 有后续元素
this.next.toArrayNode(); // 继续下一个数据的取得
}
}
}
// ===================== 以上为内部类 ===================
private Node root; // 根节点定义
private int count = 0 ; // 保存元素的个数
private int foot = 0 ; // 节点索引
private Book [] retArray ; // 返回的数组
/**
* 用户向链表增加新的数据,在增加时要将数据封装为Node类,这样才可以匹配节点顺序
* @param data 要保存的数据
*/
public void add(Book data) { // 假设不允许有null
if (data == null) { // 判断数据是否为空
return; // 结束方法调用
}
Node newNode = new Node(data); // 要保存的数据
if (this.root == null) { // 当前没有根节点
this.root = newNode; // 保存根节点
} else { // 根节点存在
this.root.addNode(newNode); // 交给Node类处理节点的保存
}
this.count ++ ; // 数据保存成功后保存个数加一
}
/**
* 取得链表中保存的数据个数
* @return 保存的个数,通过count属性取得
*/
public int size() { // 取得保存的数据量
return this.count;
}
/**
* 判断是否是空链表,表示长度为0,不是null
* @return 如果链表中没有保存任何数据则返回true,否则返回false
*/
public boolean isEmpty() {
return this.count == 0;
}
/**
* 数据查询操作,判断指定数据是否存在,如果链表没有数据直接返回false
* @param data 要判断的数据
* @return 数据存在返回true,否则返回false
*/
public boolean contains(Book data) {
if (data == null || this.root == null) { // 现在没有要查询的数据,根节点也不保存数据
return false ; // 没有查询结果
}
return this.root.containsNode(data) ; // 交由Node类查询
}
/**
* 根据索引取得保存的节点数据
* @param index 索引数据
* @return 如果要取得的索引内容不存在或者大于保存个数返回null,反之返回数据
*/
public Book get(int index) {
if (index > this.count) { // 超过了查询范围
return null ; // 没有数据
}
this.foot = 0 ; // 表示从前向后查询
return this.root.getNode(index) ; // 查询过程交给Node类
}
/**
* 根据索引修改数据
* @param index 要修改数据的索引编号
* @param data 新的数据内容
*/
public void set(int index, Book data) {
if (index > this.count) { // 判断是否超过了保存范围
return; // 结束方法调用
}
this.foot = 0; // 重新设置foot属性的内容,作为索引出现
this.root.setNode(index, data); // 交给Node类设置数据内容
}
/**
* 链表数据的删除操作,在删除前要先使用contains()判断链表中是否存在指定数据
* 如果要删除的数据存在,则首先判断根节点的数据是否为要删除数据
* 如果是,则将根节点的下一个节点作为新的根节点
* 如果要删除的数据不是根节点数据,则将删除操作交由Node类的removeNode()方法完成
* @param data 要删除的数据
*/
public void remove(Book data) {
if (this.contains(data)) { // 主要功能是判断数据是否存在
// 要删除数据是否是根节点数据,root是Node类的对象,此处直接访问内部类的私有操作
if (data.equals(this.root.data)) { // 根节点数据为要删除数据
this.root = this.root.next; // 空出当前根节点
} else { // 根节点数据不是要删除数据
// 此时根元素已经判断过了,从第二个元素开始判断,即第二个元素的上一个元素为根节点
this.root.next.removeNode(this.root, data);
}
this.count--; // 删除成功后个数要减少
}
}
/**
* 将链表中的数据转换为对象数组输出
* @return 如果链表没有数据返回null,如果有数据则将数据变为对象数组后返回
*/
public Book[] toArray() {
if (this.root == null) { // 判断链表是否有数据
return null; // 没有数据返回null
}
this.foot = 0; // 脚标清零操作
this.retArray = new Book[this.count]; // 根据保存内容开辟数组
this.root.toArrayNode(); // 交给Node类处理
return this.retArray; // 返回数组对象
}
public void clear() {
this.root = null; // 清空链表
this.count = 0; // 元素个数为0
}
}public class LinkDemo {
public static void main(String args[]) {
Link all = new Link(); // 创建链表对象
all.add(new Book("Java开发实战经典",79.8)); // 保存数据
all.add(new Book("Oracle开发实战经典",89.8)); // 保存数据
all.add(new Book("Android开发实战经典",99.8)); // 保存数据
System.out.println("保存书的个数:" + all.size()) ;
System.out.println(all.contains(new Book("Java开发实战经典",79.8))) ;
all.remove(new Book("Android开发实战经典",99.8)) ;
Book [] books = all.toArray() ;
for (int x = 0 ; x < books.length ; x ++) {
System.out.println(books[x].getInfo()) ;
}
}
}public class LinkDemo {
public static void main(String args[]) {
Link all = new Link(); // 创建链表对象
all.add(new Book("Java开发实战经典",79.8)); // 保存数据
all.add(new Book("Oracle开发实战经典",89.8)); // 保存数据
all.add(new Book("Android开发实战经典",99.8)); // 保存数据
System.out.println("保存书的个数:" + all.size()) ;
System.out.println(all.contains(new Book("Java开发实战经典",79.8))) ;
all.remove(new Book("Android开发实战经典",99.8)) ;
Book [] books = all.toArray() ;
for (int x = 0 ; x < books.length ; x ++) {
System.out.println(books[x].getInfo()) ;
}
}
}本程序首先在链表中修改了其保存的数据类型与对象比较方法,然后实例化了 Link 类对象,并且保存了多个 Book 类对象。最终可以发现由于对象比较方法的成功编写,contains() 与 remove() 两个方法可以正常操作。