计算机科学入门
之前我们深入讨论了电线信号交换机数据包,路由器以及协议,它们共同组成了互联网,今天我们向上再抽象一层,来讨论 万维网 (World Wide Web)。
万维网
万维网 (World Wide Web),和 互联网 (Internet) 不是一回事 ,尽管人们经常混用这两个词。
万维网在互联网 之上 运行,互联网之上还有 Skype , Minecraft 和 Instagram 。

互联网是传递数据的管道,各种程序都会用,其中传输最多数据的程序是万维网,分布在全球数百万个服务器上,可以用 浏览器 (web browser)来访问万维网。
超链接
万维网的最基本单位,是 单个页面 ,页面有内容,也有去往其他页面的链接,这些链接叫 超链接 (hyperlinks)。

你们都见过可以点击的文字或图片,把你送往另一个页面,这些超链接形成巨大的互联网络,这就是 万维网 名字的由来。
现在说起来觉得很简单,但在超链接做出来之前,计算机上每次想看另一个信息时,你需要在 文件系统 中找到它,或是把地址输入搜索框,有了超链接,你可以在相关主题间轻松切换。
超链接的价值早在 1945 年,就被 Vannevar Bush 意识到了,之前我们说过,他发过一篇文章,描述一个假想的机器 Memex 。
Bush的形容是 "关联式索引,选一个物品会引起另一个物品被立即选中" 。
他解释道:"将两样东西联系在一起的过程十分重要,在任何时候,当其中一件东西进入视线,只需点一下按钮,立马就能回忆起另一件"。
1945 年的时候计算机连显示屏都没有,所以这个想法非常超前!
因为文字超链接是如此强大,它得到了一个同样厉害的名字: 超文本 (hypertext)!
如今超文本最常指向的,是另一个网页,然后网页由浏览器渲染,我们待会会讲。
URL
为了使网页能相互连接,每个网页需要一个唯一的地址,这个地址叫 统一资源定位器 (Uniform Resource Locator),简称 URL 。
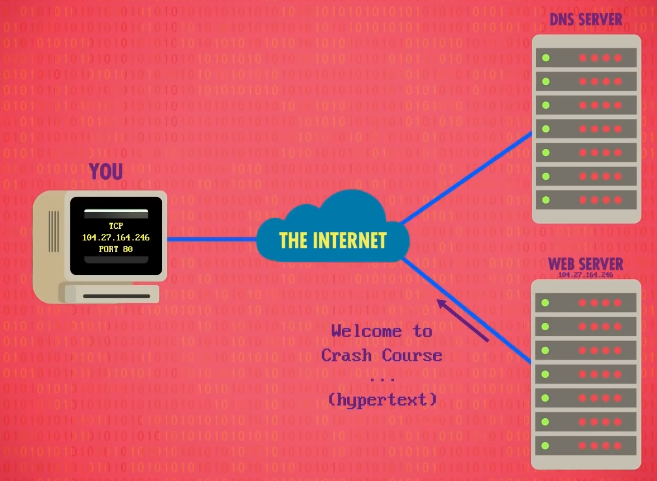
当你访问一个网站时,计算机首先会做 DNS查找 ,DNS 会输出对应的 IP 地址。
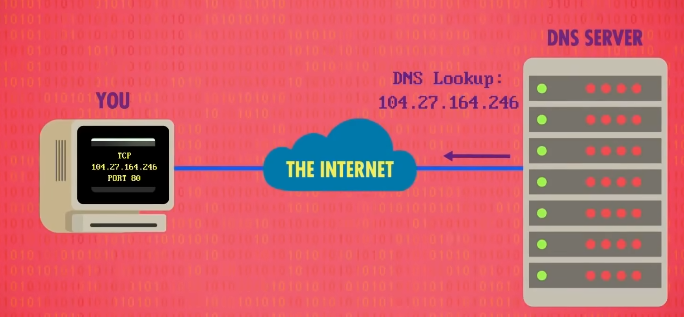
现在有了 IP 地址,你的浏览器会打开一个 TCP 连接到这个 IP 地址,这个地址运行着 网页服务器 ,网页服务器的标准端口是 80 端口。
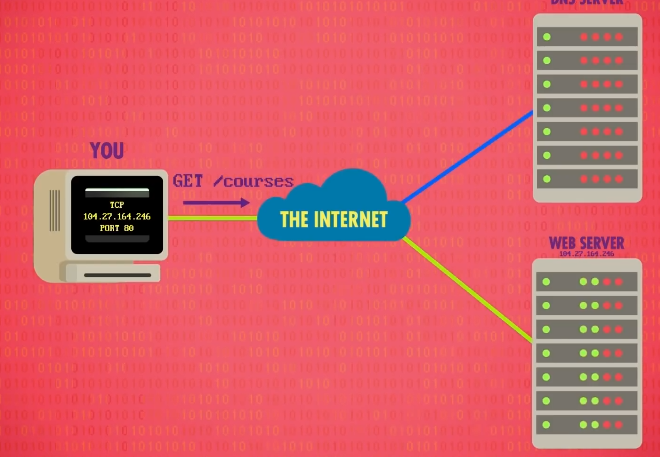
这时,你的计算机连到了服务器,下一步是向服务器请求 courses 这个页面,这里会用 超文本传输协议 (Hypertext Transfer Protocol),简称 HTTP 。
HTTP
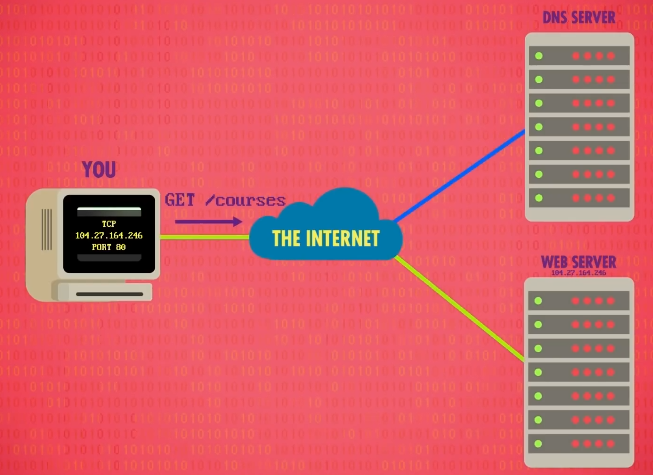
HTTP 的第一个标准,HTTP0.9 ,创建于 1991 年,只有一个指令, GET 指令。
幸运的是,对当时来说也够用,因为我们想要的是 courses 页面,我们向服务器发送指令: GET/courses ,该指令以 ASCII编码 发送到服务器。
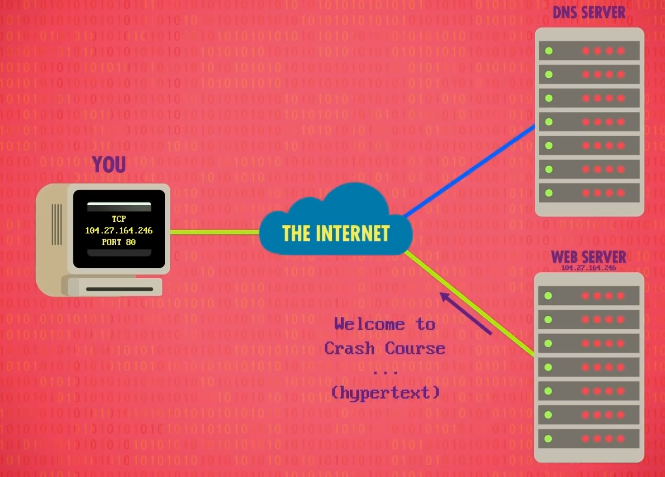
服务器会返回该地址对应的网页,然后浏览器会渲染到屏幕上,如果用户点了另一个链接,计算机会重新发一个 GET 请求,你浏览网站时,这个步骤会不断重复。
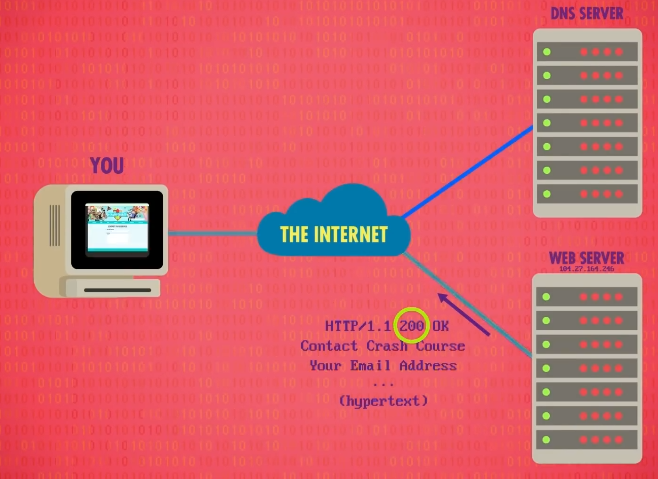
在之后的版本,HTTP 添加了 状态码 (status codes),状态码放在请求前面。
举例,状态码 200 代表 网页找到了,给你 ,状态码 400~499 代表 客户端出错 ,比如网页不存在,就是可怕的 404 错误。
TIP
HTTP 将在专门的板块详细阐述。
HTML
超文本 的存储和发送都是以普通文本形式,举个例子,编码可能是 ASCII 或 UTF-16 ,因为如果只有纯文本,无法表明什么是链接,什么不是链接,所以有必要开发一种标记方法,因此开发了 超文本标记语言 (Hypertext Markup Language),简称 HTML 。
HTML 第一版的版本号是 0.8 ,创建于 1990 年,有 18 种 HTML 指令。
首先,给网页一个大标题,我们输 h1 代表一级标题,然后用 <> 括起来,这就是一个 HTML 标签,然后输入想要的标题,我们不想一整页都是标题,所以加 </h1> 作为结束标签。

现在来加点内容,读者可能不知道 克林贡 是什么,所以我们给这个词,加一个超链接到 克林贡语言研究院 。
我们用 <a> 标签来做,它有一个 href 属性,说明链接指向哪里,当点击链接时就会进入那个网页,最后用 </a> 关闭标签。
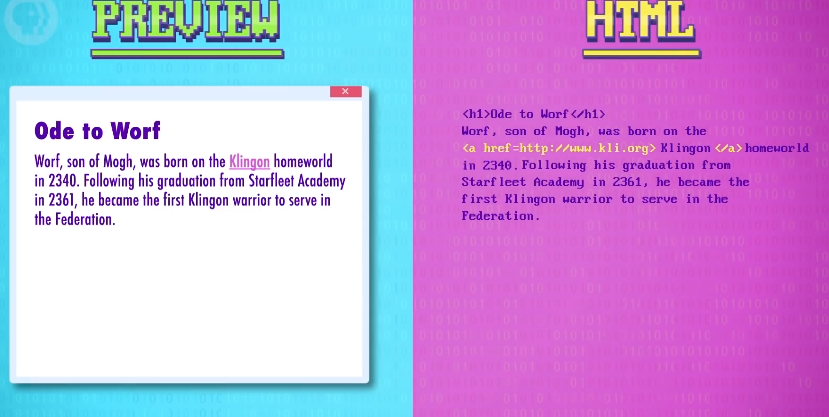
接下来用 <h2> 标签做二级标题,HTML 也有做列表的标签,我们先写 <ol> ,代表 有序列表 (orderedlist),然后想加几个列表项目就加几个,用 <li> 包起来就行。
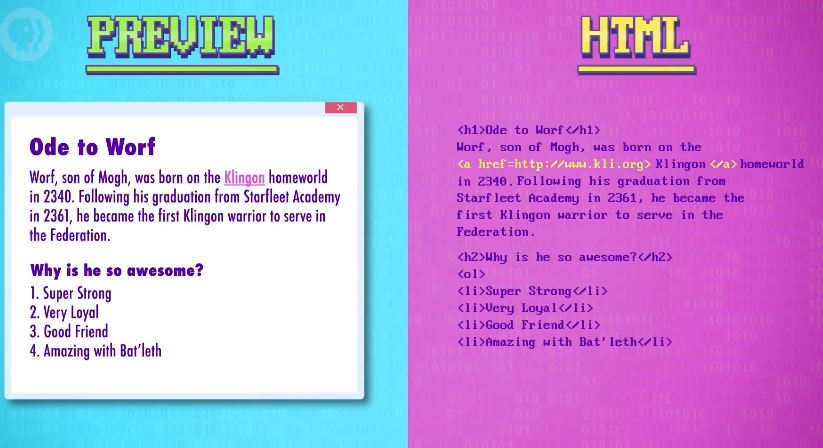
读者可能不知道 Bat'leth 是什么,那么也加上超链接,最后,为了保持良好格式,用 </ol> 代表列表结束。
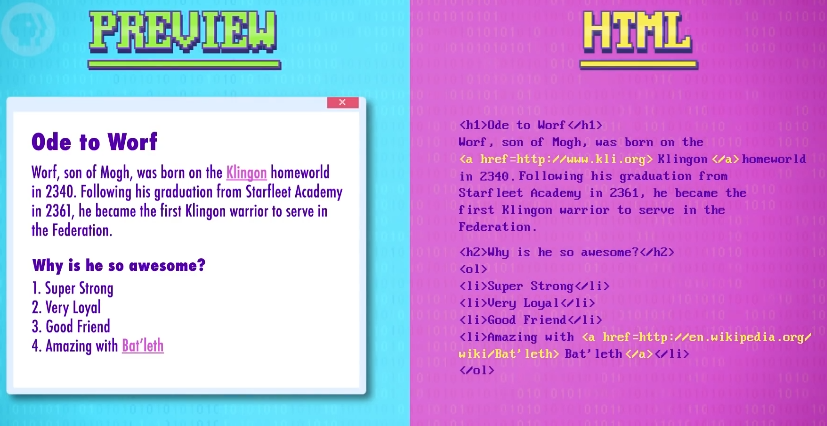
这就完成了-一个很简单的网页!
如果把这些文字存入记事本或文本编辑器,,然后文件取名 test.html ,就可以拖入浏览器打开。

当然,如今的网页更复杂一些,最新版的 HTML,HTML5,有 100 多种标签,图片标签,表格标签,表单标签,按钮标签,等等。
还有其他相关技术就不说了,比如 层叠样式表 (CSS)和 JavaScript ,这俩可以加进网页,做一些更厉害的事。
TIP
HTML、CSS、JavaScript 将在专门的板块详细阐述。
浏览器
让我们回到浏览器,网页浏览器可以和网页服务器沟通,浏览器不仅获取网页和媒体,获取后还负责显示。
第一个浏览器和服务器是 TimBerners-Lee 在1990年写的,一共花了2个月,那时候他在瑞士的 欧洲核子研究所 工作。
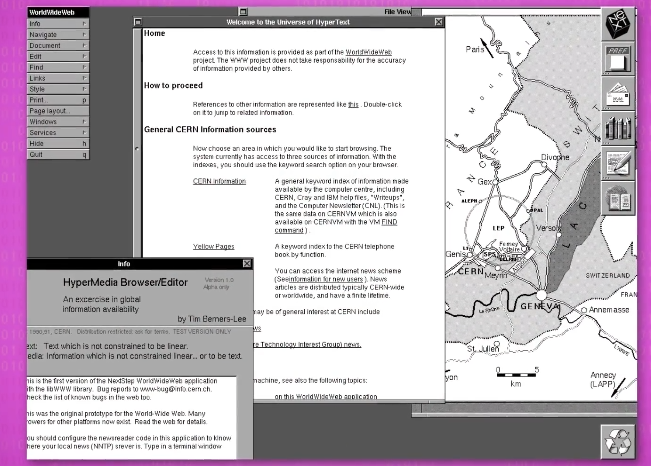
为了做出来,他同时建立了几个最基本的网络标准,URL,HTML 和 HTTP。
两个月能做这些很不错啊!不过公平点说,他研究超文本系统已经有十几年了。
和同事在 CERN 内部使用一阵子后,在 1991 年发布了出去,万维网就此诞生。
重要的是,万维网有开放标准,大家都可以开发新服务器和新浏览器。
因此 伊利诺伊大学香槟分校 的一个小组,在 1993 年做了 Mosaic 浏览器 ,第一个可以在文字旁边 显示图片 的浏览器,之前浏览器要单开一个新窗口显示图片。
还引进了书签等新功能,界面友好,使它很受欢迎,尽管看上去硬邦邦的,但和如今的浏览器长的差不多。
1990 年代末有许多浏览器面世,Netscape Navigator,Internet Explorer,Opera,Omni Web,Mozilla。
也有很多服务器面世,比如 Apache 和 微软互联网信息服务 (IIS)每天都有新网站冒出来。
如今的网络巨头,比如亚马逊和 eBay ,创始于 1990 年代中期,那是个黄金时代!
搜索引擎
随着万维网日益繁荣,人们越来越需要 搜索 ,如果你知道网站地址,比如 ebay.com ,直接输入浏览器就行,如果不知道地址呢?
起初人们会维护一个目录,链接到其他网站,其中最有名的叫 Jerry和David的万维网指南 ,1994年改名为 Yahoo (雅虎)。
随着网络越来越大,人工编辑的目录变得不便利,所以开发了搜索引擎。
长的最像现代搜索引擎的最早搜素引擎,叫 Jump Station ,由 Jonathon Fletcher 于 1993 年在斯特林大学创建。

它有 3 个部分,第一个是 爬虫 ,一个跟着链接到处跑的软件,每当看到新链接,就加进自己的列表里。
第二个部分是不断扩张的 索引 ,记录访问过的网页上,出现过哪些词。
最后一个部分, 是查询索引的 搜索算法 。
举个例子,如果我在 Jump Station 输入"猫",每个有 "猫" 这个词的网页都会出现。
早期搜索引擎的排名方式非常简单,取决于搜索词在页面上的出现次数,刚开始还行,直到有人开始钻空子,比如在网页上写几百个 "猫" ,把人们吸引过来。
谷歌成名的一个很大原因是,创造了一个聪明的 算法 来规避这个问题,与其信任网页上的内容,搜索引擎会看其他网站有没有链接到这个网站,如果只是写满 "猫" 的垃圾网站,没有网站会指向它,如果有关于猫的有用内容,有网站会指向它,所以这些 "反向链接" 的数量,特别是有信誉的网站,代表了网站质量,这个算法以他自己的名字命名,叫做 佩奇算法 。
Google 一开始时是 1996 年斯坦福大学,一个叫 BackRub 的研究项目,两年后分离出来,演变成如今的谷歌。
网络中立性
最后我想讲一个词,你最近可能经常听到, 网络中立性 (Net Neutrality)。
现在你对数据包,路由和万维网,有了个大体概念,足够你理解这个争论的核心点,至少从技术角度。
简单说 网络中立性 是应该 平等对待 所有数据包,不论这个数据包是我的邮件,或者是你在看视频,速度和优先级应该是一样的。
但很多公司会乐意让它们的数据优先到达,拿 Comcast 举例,它们不但是大型互联网服务提供商,而且拥有多家电视频道,比如NBC和The Weather Channel,可以在线看。

但要是没有网络中立性,Comcast 可以让自己的内容优先到达,节流 其他线上视频,节流 (Throttled) 意思是故意给 更少带宽 和 更低优先级 。
支持网络中立性的人说,没有中立性后,服务商可以推出提速的 "高级套餐" ,给剥削性商业模式埋下种子。
互联网服务供应商成为信息的 "守门人" ,它们有着强烈的动机去碾压对手,另外,Netflix 和 Google 这样的大公司可以花钱买特权,而小公司,比如刚成立的创业公司,会处于劣势,阻止了创新。

另一方面,从技术原因看,也许你会希望不同数据传输速度不同,你希望 Skype 的优先级更高,邮件晚几秒没关系。
而反对 网络中立性 的人认为,市场竞争会阻碍不良行为,如果供应商把客户喜欢的网站降速,客户会离开供应商,这场争辩还会持续很久。
你应该自己主动了解更多信息,因为 网络中立性 的影响十分复杂而且广泛。