计算机科学入门
上次我们讨论了计算机视觉,让电脑能看到并理解,今天我们讨论怎么让计算机理解 语言 。
你可能会说:计算机已经有这个能力了,在之前,我们聊了 机器语言 和更高层次的 编程语言 。
虽然从定义来说它们也算语言,但词汇量一般很少,而且非常 结构化 ,代码只能在拼写和语法完全正确时,编译和运行。
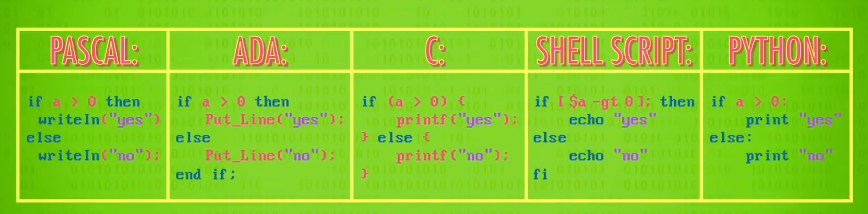
自然语言处理
当然,这和人类语言完全不同,人类语言叫 自然语言 (natural language),自然语言有大量词汇,有些词有多种含义,不同口音,以及各种有趣的文字游戏。

人们在写作和说话时也会犯错,比如单词拼在一起发音,关键细节没说导致意思模糊两可,以及发错音。
但大部分情况下,另一方能理解,人类有强大的语言能力,因此,让计算机拥有语音对话的能力这个想法从构思计算机时就有了。
自然语言处理 (Natural Language Processing)因此诞生,简称 NLP ,结合了计算机科学和语言学的一个跨学科领域,单词组成句子的方式有无限种,我们没法给计算机一个字典,包含所有可能句子,让计算机理解人类在嘟囔什么。
所以 NLP 早期的一个基本问题是: 怎么把句子切成一块块 ,这样更容易处理。
上学时,老师教你英语单词有九种基本类型: 名词,代词,冠词,动词,形容词,副词,介词,连词和感叹词 ,这叫 词性 (parts of speech)。
还有各种子类,比如 单数名词 vs 复数名词 , 副词最高级 vs 副词比较级 。
但我们不会深入那些,了解单词类型很有用,但不幸的是,很多词有多重含义比如 rose 和 leaves ,可以用作 名词 或 **动词 ** 。
短语结构规则
仅靠字典,不能解决这种模糊问题,所以电脑也要知道 语法 。
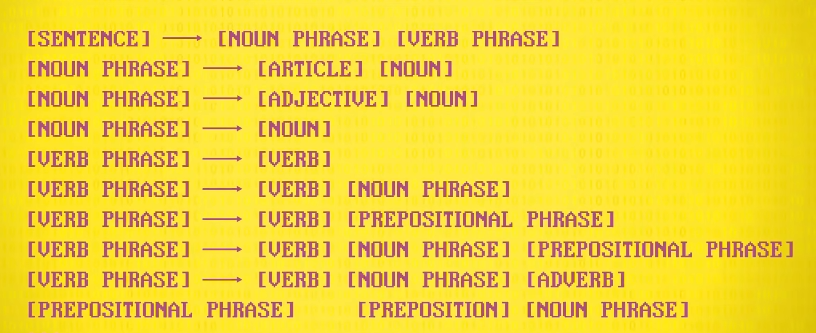
因此开发了 短语结构规则 (phrase structure rules)来代表语法规则。
例如,英语中有一条规则,句子可以由 一个名词短语 和 一个动词短语 组成,名词短语可以是冠词,如 the ,然后一个名词,或一个形容词后面跟一个名词,你可以给一门语言制定出一堆规则。
用这些规则,可以做出 分析树 (parse tree),它给每个单词标了可能是什么词性,也标明了句子的结构,数据块 更小 更容易处理。
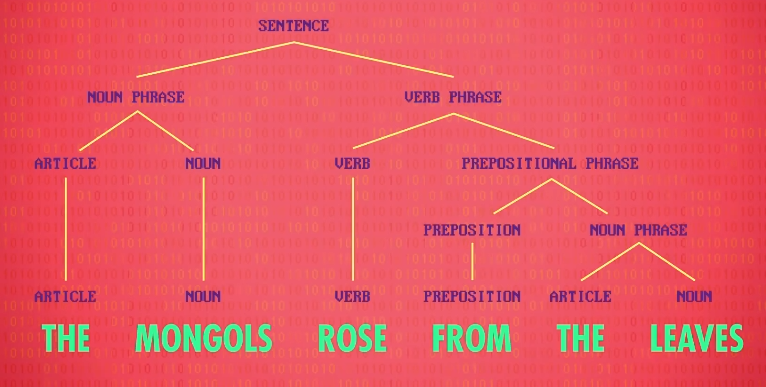
每次语音搜索,都有这样的流程,比如 最近的披萨在哪里 ,计算机能明白这是 哪里(where)的问题,知道你想要名词 披萨 (pizza),而且你关心的维度是 最近的 (nearest)。
最大的长颈鹿是什么? 或 Thriller 是谁唱的? ,也是这样处理,把语言像乐高一样拆分,方便计算机处理。
计算机可以回答问题以及处理命令,比如 设 2:20 的闹钟 或 用 Spotify 播放 T,Swizzle 。
但你可能体验过,如果句子复杂一点,计算机就没法理解了。
知识图谱
还有,短语结构规则 和其他把语言结构化的方法可以用来生成句子,数据存在语义信息网络时,这种方法特别有效,实体互相连在一起,提供构造句子的所有成分。
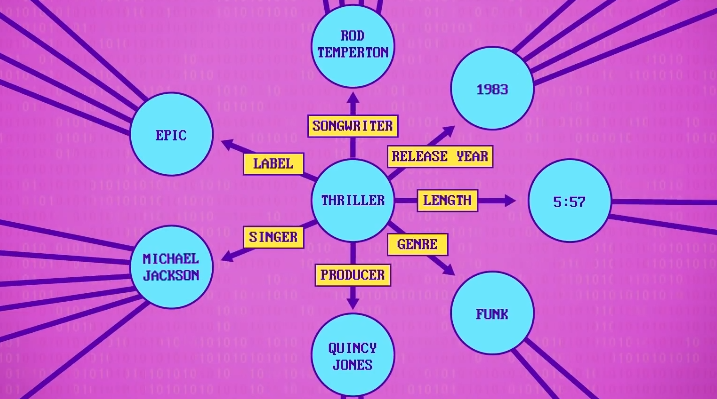
比如: Thriller于1983年发行,由迈克尔杰克逊演唱 。
Google版的叫 知识图谱 (Knowledge Graph),在 2016 年底包含大概七百亿个事实,以及不同实体间的关系,处理,分析,生成文字,是 聊天机器人 的最基本部件。
聊天机器人
聊天机器人就是能和你聊天的程序,早期聊天机器人大多用的是规则,专家把用户可能会说的话,和机器人应该回复什么,写成上百个规则,显然,这很难维护,而且对话不能太复杂。
一个著名早期例子叫 Eliza ,1960 年代中期诞生于 麻省理工学院 ,一个治疗师聊天机器人,它用基本句法规则来理解用户打的文字,然后向用户提问,有时候会感觉像和人类沟通一样,但有时会犯简单甚至很搞笑的错误。
聊天机器人和对话系统,在过去五十年发展了很多,如今可以和真人很像!
如今大多用 机器学习 ,用上 GB 的真人聊天数据来训练机器人,现在聊天机器人已经用于客服回答,客服有很多对话可以参考,人们也让聊天机器人互相聊天。
在 Facebook 的一个实验里,聊天机器人甚至发展出自己的语言,很多新闻把这个实验报导的很吓人,但实际上只是计算机,在制定简单协议来帮助沟通,这些语言不是邪恶的,而是为了效率。
但如果听到一个句子,计算机怎么从声音中提取词汇?
语音识别
这个领域叫 语音识别 (speech recognition),这个领域已经重点研究了几十年,贝尔实验室在 1952 年推出了第一个语音识别系统,绰号 Audrey ,自动 数字识别 器,如果你说得够慢,它可以识别全部十位数字。
这个项目没有实际应用,因为用键盘手输快得多。
十年后,1962 年的世界博览会上,IBM 展示了一个鞋盒大小的机器,能识别 16 个单词。

为了推进 语音识别 领域的研究,DARPA 在 1971 年启动了一项雄心勃勃的五年筹资计划,之后诞生了 卡内基梅隆大学 的 Harpy ,Harpy是第一个可以识别 1000 个单词以上的系统。
但那时的电脑语音转文字,经常比实时说话要慢十倍或以上,幸运的是,1980,1990年代计算机性能的大幅提升,实时语音识别变得可行,同时也出现了处理自然语言的新算法,不再是手工定规则,而是用 机器学习 ,从语言数据库中学习。
如今准确度最高的语音识别系统用 深度神经网络 ,为了理解原理,我们来看一些对话声音。
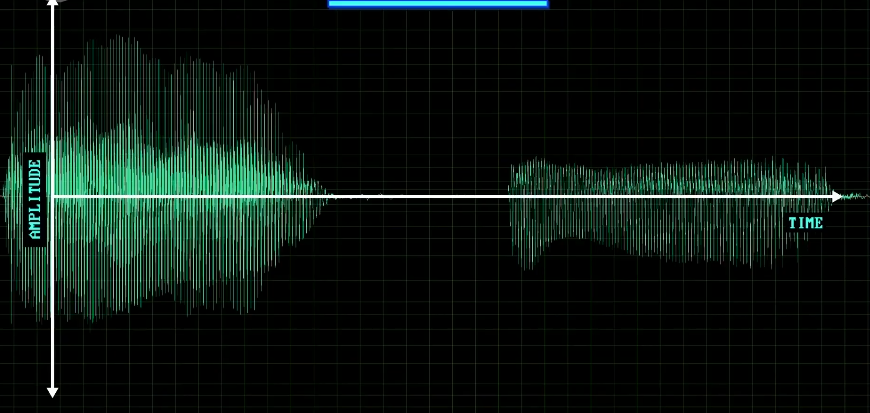
先看元音,比如 a 和 e ,这是两个声音的波形,这个信号来自麦克风内部隔膜 震动 的频率。
在这个视图中,横轴是时间,竖轴是隔膜移动的幅度,或者说振幅。
谱图
虽然可以看到 2 个波形有区别,但不能看出哪个是 e 。
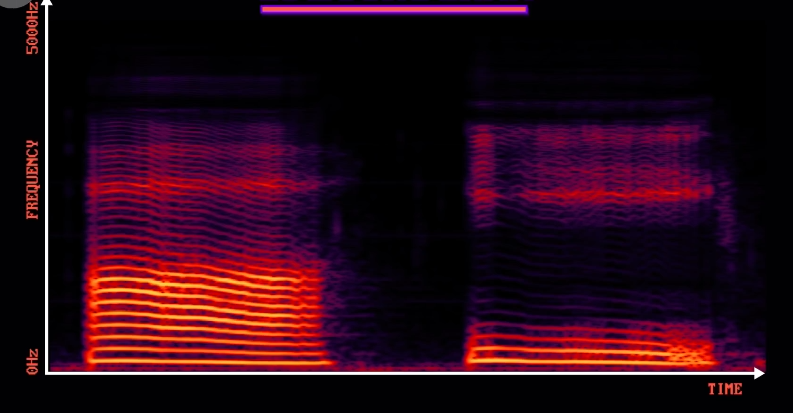
为了更容易识别,我们换个方式看: 谱图 (spectrogram)。
这里横轴还是时间,但竖轴不是振幅,而是不同频率的振幅,颜色越亮,那个频率的声音越大,这种波形到频率的转换是用一种很酷的算法做的, 快速傅立叶变换 (Fast Fourier Transform),简称 FFT 。
如果你盯过立体声系统的 EQ 可视化器,它们差不多是一回事。
谱图是随着时间变化的,你可能注意到,信号有种螺纹图案,那是我声道的 回声 。
为了发出不同声音,我要把声带,嘴巴和舌头变成不同形状,放大或减少不同的共振,可以看到有些区域更亮,有些更暗。

如果从底向上看,标出高峰,叫 共振峰 (formants),可以看到有很大不同,所有元音都是如此。
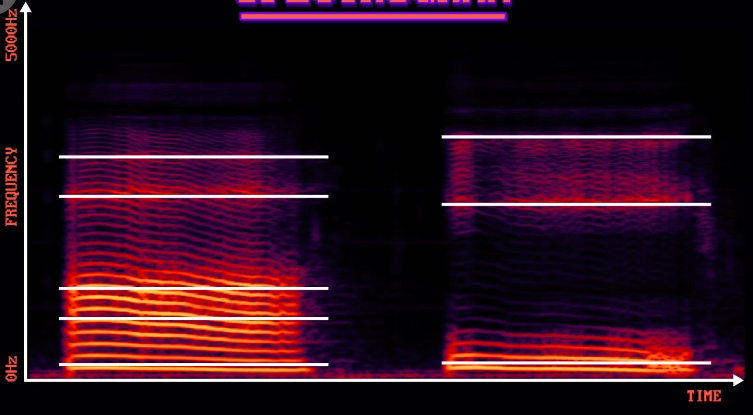
这让计算机可以识别元音,然后识别出整个词。
让我们看一个更复杂的例子,当我说 她..很开心 的时候,可以看到 e 声,和 a 声,以及其它不同声音。
比如 she 中的 shh 声, was 中的 wah 和 sss ,等等。

这些构成单词的声音片段叫 音素 (phonemes),语音识别软件知道这些音素,英语有大概 44 种音素,所以本质上变成了音素识别。
还要把不同的词分开,弄清句子的 开始 和 结束 点,最后把语音转成文字,使开头讨论的那些技术成为可能。
因为口音和发音错误等原因,人们说单词的方式略有不同,所以结合 语言模型 后,语音转文字的准确度会大大提高,里面有单词顺序的统计信息。
比如 她 后面很可能跟一个 形容词 ,比如 很开心 , 她 后面很少是名词,如果不确定是 happy 还是 harpy ,会选 happy ,因为语言模型认为 可能性 更高。
语音合成
最后,我们来谈谈 语音合成 (Speech Synthesis),让计算机 输出 语音,它很像语音识别,不过反过来,把一段文字,分解成多个声音,然后播放这些声音。
早期语音合成技术,可以清楚听到 音素 是拼在一起的,比如这个 1937 年贝尔实验室的手动操作机器,不带感情的说 她看见了我 。
到了 1980 年代,技术改进了很多,但音素混合依然不够好,产生明显的机器人声。
如今,电脑合成的声音,比如 Siri ,Cortana ,Alexa 好了很多,但还不够像人,但我们非常非常接近了,这个问题很快会被解决。
现在语音界面到处都是,手机里,汽车里,家里,也许不久之后耳机也会有。
这创造一个 正反馈 循环,人们用语音交互的频率会提高,这又给了谷歌,亚马逊,微软等公司 更多数据 来训练语音系统,提高准确性。
准确度高了,人们更愿意用语音交互,越用越好,越好越用。
很多人预测,语音交互会越来越常见,就像如今的屏幕,键盘,触控板等设备,这对机器人发展是个好消息,机器人就不用走来走去时带个键盘和人类沟通。